8. Semantic Segmentation
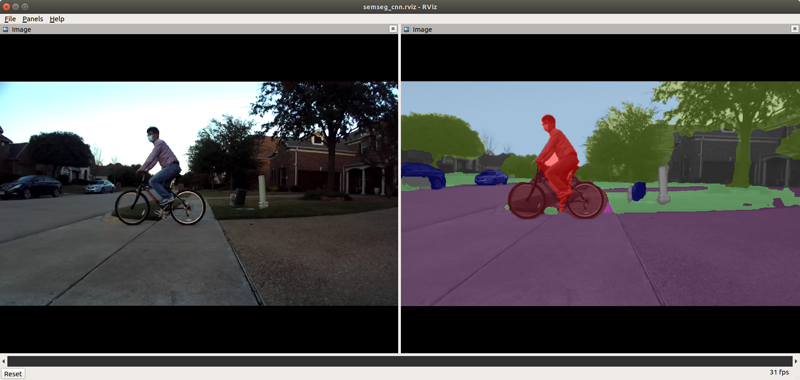
This ti_vision_cnn node is a versatile deep-learning (DL) inference ROS node that is optimized on DL cores and hardware accelerator of TI Processors. The ti_vision_cnn node supports compute-intensive DL inference operations, including 2D object detection and semantic segmentation. Figure 1 shows the high-level block diagram of the applications around the ti_vision_cnn node, which consists of multiple processing blocks that are deployed on hardware accelerators and DSP processors for pre-processing and post-processing in an optimized manner.

8.1. System Description
Referring to Figure 1, below are the descriptions of the processing blocks implemented in this application:
The first step to process input images with lens distortion is performed by the LDC (Lens Distortion Correction) hardware accelerator (HWA), which handles the undistortion or rectification. Tools for generating LDC look-up-tables are provided with the SDK (
tools/stereo_camera/generate_rect_map.pyandtools/mono_camera/generate_rect_map_mono.py). Note that the LDC HWA not only removes lens distortion or rectifies, but also changes the image format. Input image to the application is in YUV422 (UYVY) format, which is converted to YUV420 (NV12) by the LDC.Input images are resized to match to the input tensor size of the semantic segmentation model. The MSC (Multi-Scaler) HWA resizes the images to a desired size.
Input images are resized to match the input tensor size required by the semantic segmentation model. This resizing to the desired size. is done by the MSC (Multi-Scaler) HWA.
The pre-processing block, which runs on C6x, converts the YUV420 (NV12) format to RGB. This RGB format is the expected input format for the semantic segmentation model.
The semantic segmentation network is accelerated by C7x/MMA with DLR runtime and outputs a tensor that contains class information for every pixel.
8.2. Semantic Segmentation Model
A CNN model for semantic segmentation has been developed using Jacinto AI DevKit (PyTorch).
Model: deeplabv3lite_mobilenetv2_tv (for details, see LINK)
Input image: 768 x 432 pixels in RGB
Training data: Cityscapes Dataset, and a small dataset collected from ZED camera
Note
cam_id and subdev_id for cameras: You can check the device_id and subdev_id for the camera
attached to the SK board by running /opt/edgeai-gst-apps/scripts/setup_cameras.sh. Accordingly please update the parameters or pass as launch arguments.
Note
IMX390 Camera: Before running, please refer to gscam2/README_TI.md for generating required LUT files for tiovxldc.
8.3. Run the Application in ROS 2
[SK] To launch the semantic segmentation demo with a ZED stereo camera, run the following command inside the ROS 2 Docker container on the target:
ros2 launch ti_vision_cnn zed_semseg_cnn_launch.py cam_id:=x zed_sn:=SNxxxxx
To process the image stream from a USB mono camera:
ros2 launch ti_vision_cnn gscam_semseg_cnn_launch.py cam_id:=x
For IMX219 camera as input,
ros2 launch ti_vision_cnn gscam_semseg_cnn_imx219_launch.py cam_id:=x subdev_id=y
For IMX390 camera as input, depending on choice of resolution, run one from the following commands.
ros2 launch ti_vision_cnn gscam_semseg_cnn_imx390_launch.py cam_id:=x subdev_id=y width:=1920 height:=1080
ros2 launch ti_vision_cnn gscam_semseg_cnn_imx390_launch.py cam_id:=x subdev_id=y width:=1280 height:=720
ros2 launch ti_vision_cnn gscam_semseg_cnn_imx390_launch.py cam_id:=x subdev_id=y width:=960 height:=540
[Visualization on Ubuntu PC] For setting up environment of the remote PC, please follow Docker Setup for ROS 2
Depending on the resolution setting of the capture node, run one from the following:
ros2 launch ti_viz_nodes rviz_semseg_cnn_launch.py width:=1920 height:=1080
ros2 launch ti_viz_nodes rviz_semseg_cnn_launch.py width:=1280 height:=720 $ default for USB camera and IMX219
ros2 launch ti_viz_nodes rviz_semseg_cnn_launch.py width:=960 height:=540
8.4. Launch File Parameters
Parameter |
Description |
Value |
|---|---|---|
rosparam file |
Algorithm configuration parameters (see “ROSPARAM Parameters” section) |
config/params.yaml |
image_format |
Input image format: 0 - VX_DF_IMAGE_U8, 1 - VX_DF_IMAGE_NV12, 2 - VX_DF_IMAGE_UYVY |
0, 1, 2 |
enable_ldc_node |
LDC node enable/disable flag |
0, 1 |
lut_file_path |
LDC rectification table path |
String |
dl_model_path |
DL model artifacts folder path |
String |
input_topic_name |
Subscribe topic name for input camera image |
camera/right/image_raw |
rectified_image_topic |
Publish topic name for output rectified image |
camera/right/image_rect_nv12 |
rectified_image_frame_id |
frame_id for output rectified image |
right_frame |
vision_cnn_tensor_topic |
Publish topic name for output tensor |
vision_cnn/tensor |
exportPerfStats |
Flag for exporting the performance data to a file: 0 - disable, 1 - enable |
0, 1 |
8.5. ROSPARAM Parameters
The table below describes the parameters in config/params.yaml:
Parameter |
Description |
Value |
|---|---|---|
width |
Input image width |
Integer |
height |
Input image height |
Integer |
num_classes |
Number of semantic segmentation classes |
0 - 20 |
pipeline_depth |
OpenVX graph pipeline depth |
1 - 4 |
8.6. Known Issue
The default semantic segmentation CNN was initially trained with the Cityscapes dataset and subsequently re-trained with a small dataset collected from a stereo camera (ZED camera, HD mode). This re-training was done for a limited set of scenarios with coarse annotation. As a result, the model’s accuracy performance may be limited when used with a different camera model or in different environmental scenes.