1.3. Compiling Models¶
TI TVM supports two options for compiling models with TIDL offload. The distinction is based on where layers that are not supported by TIDL are executed during inference:
Executing unsupported layers on Arm (See flow in Figure 1).
Executing unsupported layers on C7x (See flow in Figure 2). This option frees up the Arm device to run other aspects of the application. It can also improve overall inference performance by minimizing communication across the Arm and C7x.
The following figures show components added by TIDL and the TI TVM fork outlined in red.
Model compilation with TIDL unsupported layers |
||
|---|---|---|
Mapped to Arm |
Mapped to C7x |
|

|
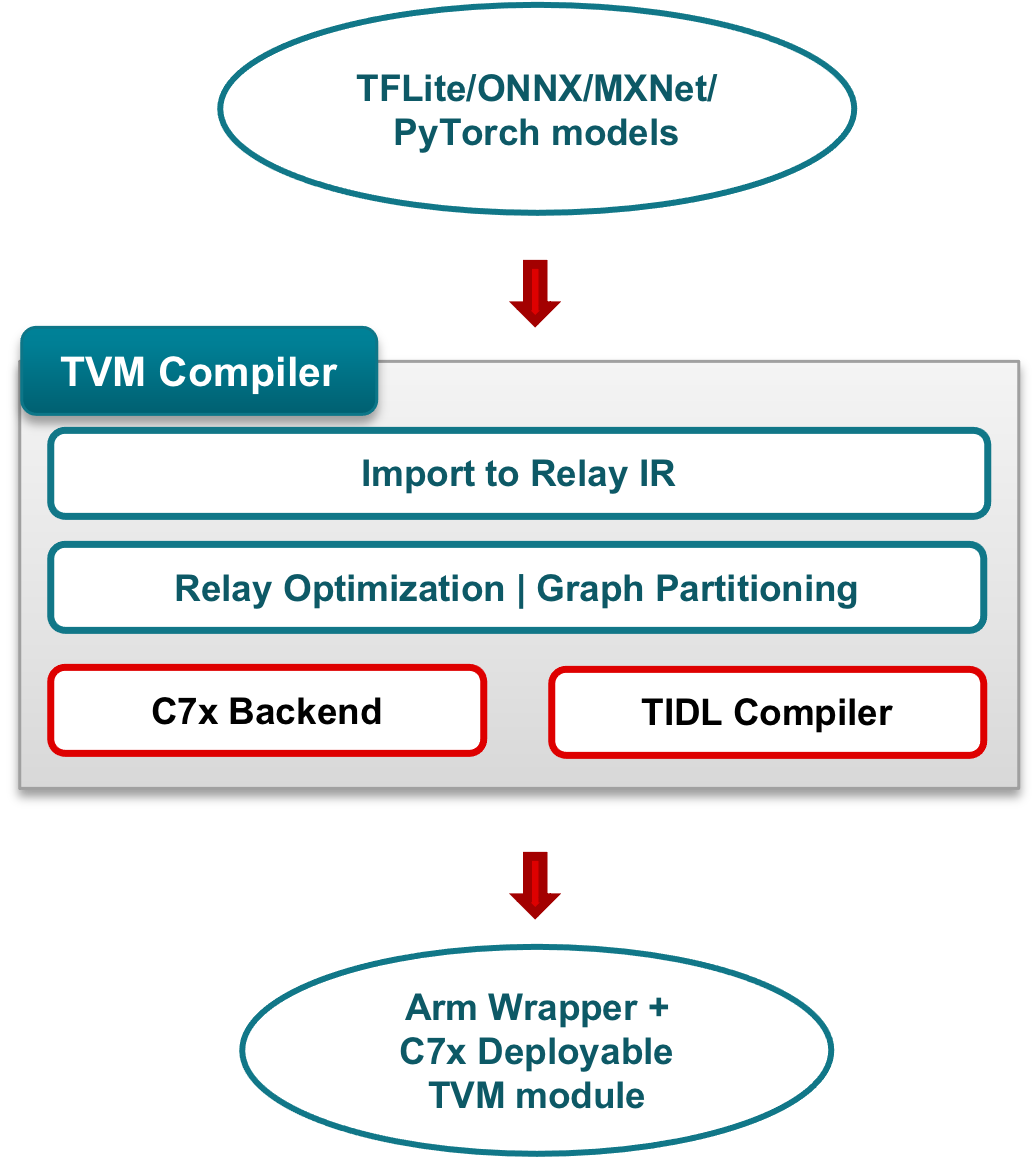
|
|
See Compilation Explained for further details about TI TVM compilation.
1.3.1. Compiling for TIDL Offload¶
TVM compilation is typically performed using a Python compilation script. Example scripts are provided in the TI edgeai-tidl-tools Git repository. You can use these examples as templates to modify for your own use cases. An overview of TI Open Source Runtime and compilation options are provided in the same repository.
The following Python functions are used in the examples provided by TI.
1.3.1.1. Compile using python interface - compile_model¶
The compile_model function encapsulates the steps required to compile a model with TIDL offload.
- tvm.contrib.tidl.compile.compile_model(platform: str, compile_for_device: bool, enable_tidl_offload: bool, delegate_options: Dict[str, Any], calibration_input_list: List[Dict[str, NDArray]], model_path: str | None = None, input_shape_dict: List[Dict[str, Any]] | None = None, mod: IRModule | None = None, params: Dict[str, NDArray] | None = None) bool[source]¶
Compile model for TVM inference based on the parameters specified.
Note either (model_path, input_shape_dict) or (mod, params) pair of parameters can be provided
- Parameters:
platform – [“am68pa”, “am68a”, “am69a”, “am67a”, “am62a] Converted internally to one of the following [“J7”, “J721S2”, “J784S4”, “J722S”, “AM62A”]
compile_for_device – True => Compile module for inference on device (aarch64). False => Compile module for inference on host (x86).
enable_tidl_offload – Set to True to enable TIDL offload.
delegate_options – TIDL offload related options specified in the form of a dictionary
calibration_input_list – A dictionary where the key is input name and the value is input tensor.
model_path ((Optional)) – Path to the model file. Supported formats: ONNX
input_shape_dict ((Optional)) – A list of dictionaries where each dictionary contains the input shape - required if model_path is specified Example: [{‘input_1’ : (1, 3, 224, 224)}]
mod ((Optional)) – Input Relay IR module.
params ((Optional)) – The parameter dict used by Relay.
- Return type:
True for success, False for failure.
After a successful compile, the artifacts required to deploy the model are stored in the artifacts_folder.
1.3.1.2. Compile using command line interface - TVMC¶
TVMC can be used to compile a model using command line as follows:
python -m tvm.driver.tvmc compile model.onnx \
--target=tidl \
--tidl-config config.yaml \
--tidl-calibration-input calibration.npz \
--enable-tidl-offload 1 \
--compile-for-device 1 \
--c7x-codegen 0 \
--output ./artifacts/
Note that this interface needs user to specify following files as input to the command:
Configuration file (–tidl-config) - The configuration file is an optional YAML file which contains compile options for TIDL. YAML file should contain a single “compile_options” section with TIDL-specific options. Values specified in this file override the default values of respective options.
Example YAML configuration file:
compile_options:
"debug_level": 1 \
"tensor_bits": 8 \
"advanced_options:calibration_frames": 2 \
"advanced_options:calibration_iterations": 5 \
"advanced_options:c7x_codegen": 1
Calibration data (–tidl-calibration-input) - Refer Calibration Data for details on calibration. TVMC expects an npz file containing data frames for calibration, so user is expected to convert image files into an npz file to be specified as input to TVMC command.
Example script to pack images into npz file for TVMC consumption.
# calib_dict - Dictionary of form - {'input_1': numpy array of N frames, 'input_2': numpy array of N frames} assuming N calibration frames \
# npz_path - Path to 'npz' file to be created \
import numpy as np \
np.savez_compressed(npz_path, **calib_dict)
After a successful compile, the artifacts required to deploy the model are stored in the artifacts_folder specified via –output option.