TI TVM User’s Guide - 11.2¶
Texas Instruments’ fork of the Apache Tensor Virtual Machine (TVM) enables support for the Jacinto/Sitara family of processors. These processors include a C7™ NPU designed to accelerate machine learning inference. For additional information about TDA4x processors and TI’s Edge AI ecosystem, refer to the Edge AI page on ti.com.
This user’s guide documents the TI TVM Compiler and its usage.
Why TI TVM?¶
TI TVM provides a complete compilation and inference runtime for deploying deep neural networks on TI’s embedded processors. Key benefits:
Unified Runtime: Single framework for compilation and inference
Hardware Acceleration: Automatic offload of supported layers to the C7™ NPU for maximum performance
Flexible Fallback: Unsupported layers execute on Arm or C7™ NPU via TVM code generation
Standard Model Support: Import models from ONNX
Production Ready: Integrated with TI’s Edge AI ecosystem
TIDL (TI Deep Learning) is TI’s software product for accelerating deep neural networks on TI’s embedded devices. It provides highly optimized implementations of common DNN layers running on the C7™ NPU, and is released as part of TI’s Processor SDK. TI TVM integrates TIDL as an accelerator backend — the compiler automatically partitions the model so that TIDL-supported layers execute with maximum hardware efficiency while TVM generates C7™ NPU code for any remaining layers.
Key Insight
TIDL handles supported operators with highly optimized C7™ NPU performance
TVM handles operators outside TIDL coverage via C7™ NPU code generation
The result: the entire model runs on C7™ NPU
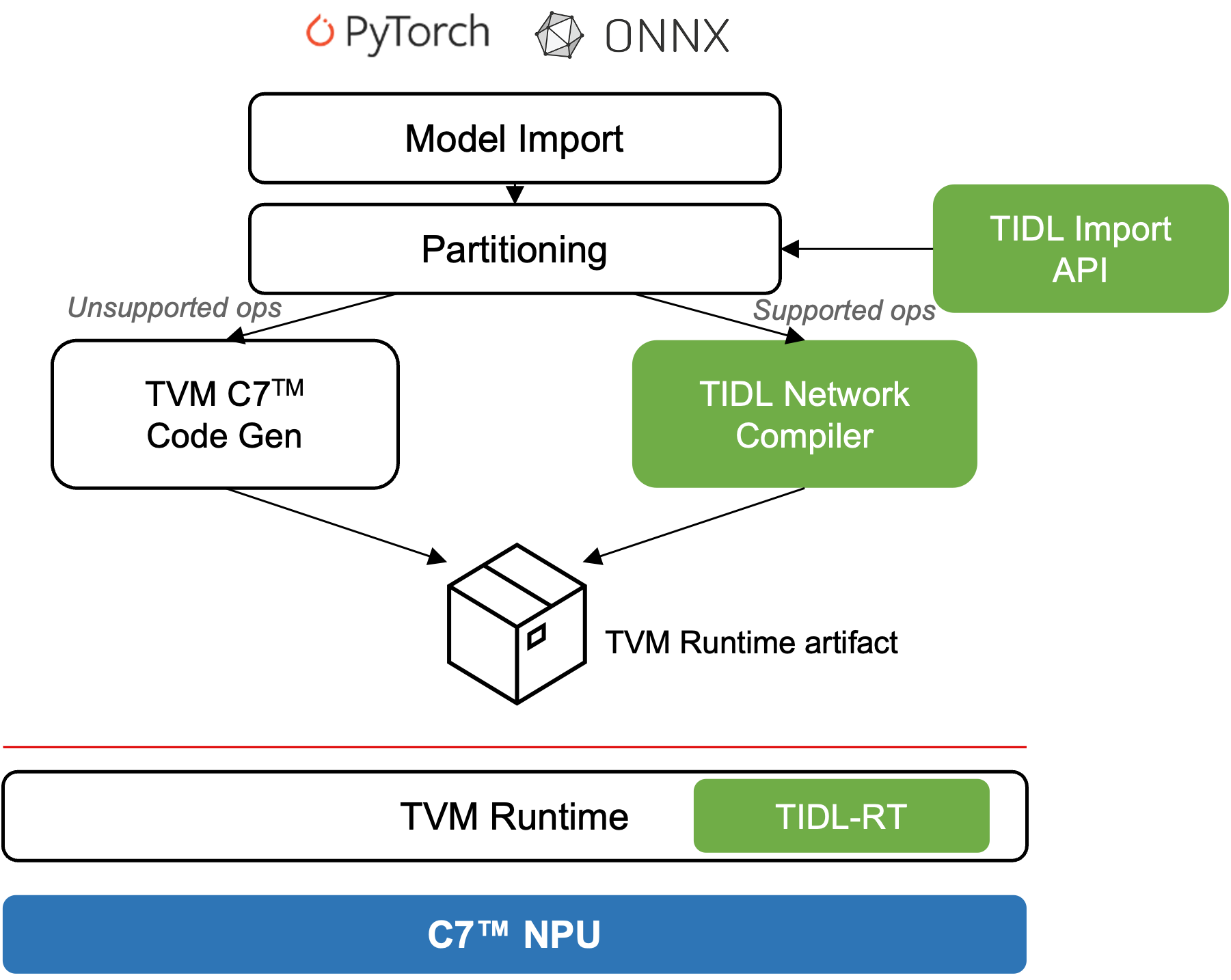
Fig. 1 TI TVM Architecture: Models are imported, partitioned between TIDL-accelerated and TVM-generated code, and compiled into a unified runtime artifact. Green components are handled by TIDL; white components are handled by TVM.¶
New to TI TVM? Start with the Getting Started chapter.