3.14. TI Deep Learning (TIDL)¶
3.14.1. Introduction¶
3.14.1.1. Deep Learning Inference in Embedded Device¶
TIDL brings deep learning to the edge by enabling applications to leverage TI’s proprietary, highly optimized CNN/DNN implementation on the EVE and C66x DSP compute engines. TIDL initially targets use cases with 2D (typically vision) data on AM57x SoCs. There are not fundamental limitations preventing the use of TIDL for 1D or 3D input data blobs.
TIDL is a set of open-source Linux software packages and tools enabling offload of Deep Learning (inference only) compute workloads from ARM cores to hardware accelerators such as EVE and/or C66x DSP. The objective for TIDL is to hide complexity of a heterogeneous device for Machine Learning/Neural network applications, and help developers focus on their specific requirements. In this way, ARM cores are freed from heavy compute load of Deep Learning task and can be used for other roles in your application. This also allows to use traditional Computer Vision (via OpenCV) augmenting Deep Learning algorithms.
At the moment, TIDL software primarily enables Convolution Neural Network inference, using offline pre-trained models, stored in device file-system (no training on target device). Models trained using Caffe or Tensorflow-slim frameworks can be imported and converted (with provided import tool) for efficient execution on TI devices.
Additional performance benefits can be achieved by doing training using Caffe-Jacinto fork of Caffe, which includes functions for making convolution weight tensor sparse, thus giving opportunity for 3x-4x performance boost of convolutions layers.
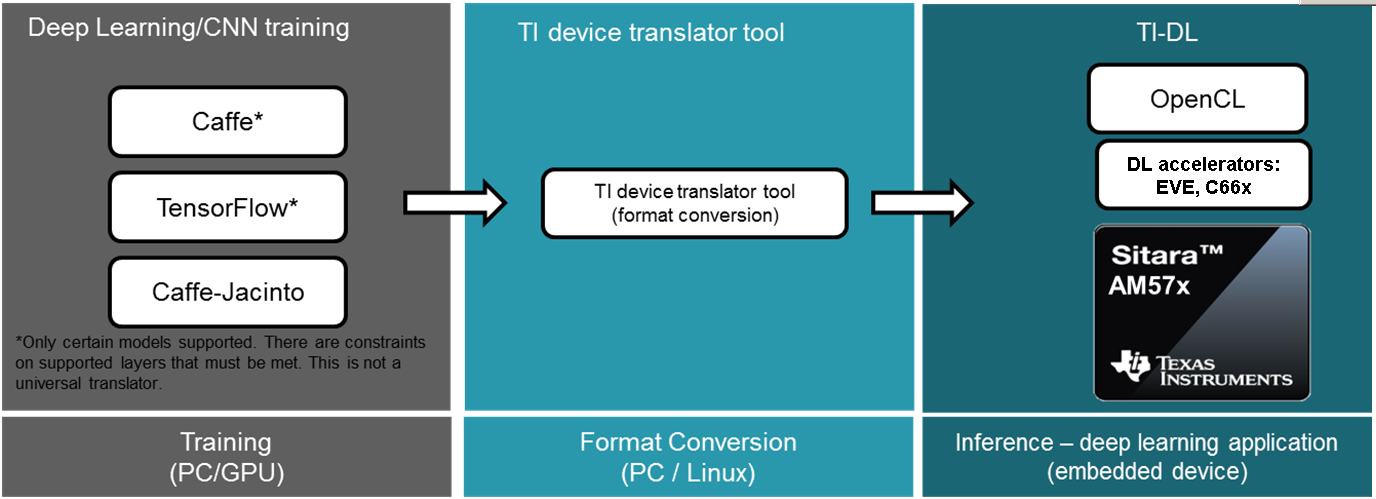
Fig. 3.3 Deep Learnining development flow on AM57xx devices
3.14.1.2. Application space¶
Current version of TIDL software is targeting Computer Vision Deep Learning applications. Example applications include vision computers, barcode readers, machine vision cameras, industrial automation systems, optical inspection systems, industrial robots, currency counters, occupancy detectors, smart appliances and unmanned vehicles. In these cases color image tensors (Width x Height x 3, for BGR planes) are typically used, but it is possible to use other data types (E.g. gray scale and depth plane: Width x Height x 2 tensor)
Based on model and task, TIDL input data are similar, but output data will vary based on task:
| Task | Output Data |
|---|---|
| Image Classification | 1D vector with likelihood of class presence. Top ranking indicates class winner (i.e. object of data class appears in input) |
| Image Pixel Segmentation | 2D matrix: Width x Height, with each cell set to integer value from 0 to max_class_index that model can discriminate |
| Image Object Detection | list of tuples. Each tuple includes class index, probability of detection, upper left corner (xmin,ymin), width and height of bounding box |
Additional examples covering other application areas (speech, audio, predictive maintenance), are in the road map. Apart from Convolution Network topologies, support for RNN/LSTM layers and topologies, targetting processing of sequential data, are planned in future releases.
3.14.1.3. Supported Devices¶
TIDL software is intended for AM57xx Sitara devices, that either have DSP or EVE, or both accelerators:
- AM5749 (2xEVEs + 2xC66x DSPs)
- AM5746 (2xC66x DSPs)
- AM572x (2xC66x DSPs)
- AM571x (1xC66x DSP)
- AM5706 (1xC66x DSP)
- AM5708 (2xC66x DSP)
3.14.1.4. Verified networks topologies¶
It is necessary to understand that TIDL is not verified against arbitrary network topology that can run in Caffe or TF. Instead, we were focused on verification of layers and network topologies that make sense to be executed on power-constraint embedded devices. Some networks are too complex for power budget of few watts. So focus is put on networks that are not extremely computationally intensive and also not having very high memory requirements. The following topologies have been verified with TIDL software:
- Jacinto11 (similar to ResNet10), classification network
- JSeg21, pixel level segmentation network
- JDetNet, (similar to SSD-300/512), object detection network
- SqueezeNet
- InceptionV1
- MobileNetV1
Here are the graphs (created using TIDL viewer tool) of first three:

Fig. 3.4 Figure Jacinto11 (resnet10 motivated)

Fig. 3.5 Figure JSeg21 (SegNet motivated)
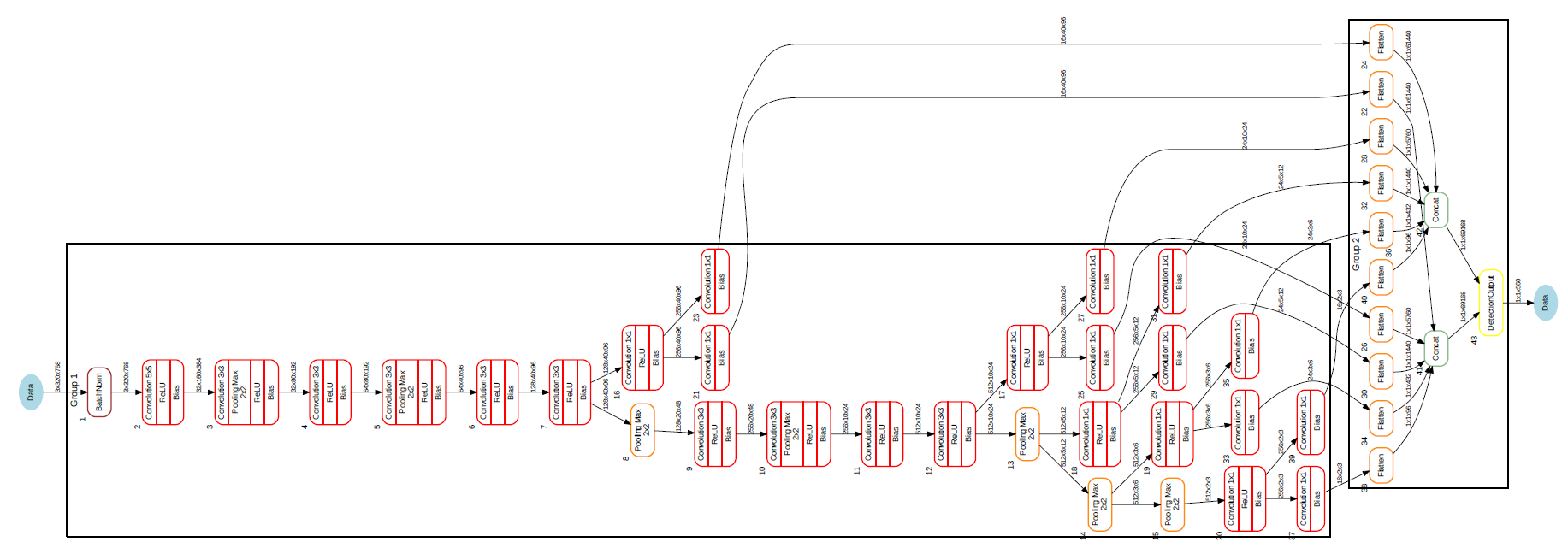
Fig. 3.6 Figure JDetNet (SSD-300/512 motivated)
Other network topologies are possible but they need to be verified. Majority of layers required (for inference only!) for classification, segmentation and detection tasks are implemented, though in some cases with certain parameter related constraints.
3.14.1.5. Neural network layers supported by TIDL¶
The following layer types/Inference features are supported:
- Convolution Layer
- Pooling Layer (Average and Max Pooling)
- ReLU Layer
- Element Wise Layer (Add, Max, Product)
- Inner Product Layer (Fully Connected Layer)
- Soft Max Layer
- Bias Layer
- Deconvolution Layer
- Concatenate layer
- ArgMax Layer
- Scale Layer
- PReLU Layer
- Batch Normalization layer
- ReLU6 Layer
- Crop layer
- Slice layer
- Flatten layer
- Split Layer
- Detection Output Layer
3.14.1.6. Constraints on layer parameters¶
Layers in current release of TIDL Lib have certain parameter related constraints:
- Convolution Layer
- Verified for kernel size up to 7x7 (Shall work for higher values also, but not validated)
- Dilation vaild for parameter values of: 1,2,4
- Stride values of 1 and 2 are supported.
- Dense convolution flow is supported for only 1x1 and 3x3 kernels with stride = 1 and dilation =1
- Maximum number of input and output channel supported: 1024.
- Deconvolution Layer
- Number of groups shall be equal to the number of channels
- Only supported stride value is 2
- Arg Max
- Up to 15 input channels are supported for EVE core and up to 6 channels are supported for DSP core
- out_max_val = false and top_k = 1 (Defaults) and axis = 1 (Supported only across channel)
- InnerProductLayer
- Maximum input and output Nodes supported are 4096
- The input data has to be flattened (That is C =1 and H =1 for the input data)
- A flatten layer can be used before this layer in C > 1 and H > 1
- If a global average Pooling also can be flattens the output
- Spatial Pooling Layer
- Average and Max Pooling are supported with stride 1, 2, 4 and kernel sizes of 2x2,3x3,4x4 etc. STOCHASTIC Pooling not supported
- Global Pooling supported for both Average and Max. The output data N=1 and H =1. The output W will be Updated with input ‘N’
- BiasLayer
- Only one scalar bias per channel is supported.
- CancatLayet
- Concatenate is only supported across channel (axis = 1; default).
- CropLayer
- Only Spatial crop is supported (axis = 2; default).
- FlattenLayer
- Keeps ‘N’ unchanged. Makes C=1 and H=1
- ScaleLayer
- Only one scalar scale and bias per channel is supported.
- SliceLayer
- Slice is only supported across channel (axis = 1; default).
- SoftmaxLayer
- The input data has to be flattened (That is C =1 and H =1 for the input data)
- SSD
- Only Caffe-Jacinto based SSD network is validated.
- Reshape, Permute layers are supported only in the context of SSD network.
- “share_location” has to be true
- Tested with 4 and 5 heads.
- SaveOutputParameter is ignored in TIDL inference.
- Code_type is only tested with CENTER_SIZE.
- Tensorflow
- Only Slim based models are validated. Please refer InceptionNetV1 and mobilenet_1.0 from below as examples for building your models.
- TF-Slim: https://github.com/tensorflow/models/tree/master/research/slim
3.14.1.7. Important TIDL API framework features¶
Current implementation of TIDL API provides following important features:
- Multiple networks on different EVEs/DSPs can run concurrently
We can run concurrently as many different networks as we have available accelerators. In case of AM5749 maximum number would be 4 (2 on 2xEVE and 2 on 2xDSP) - may need increase in default CMEM block size (~64MB per accelerator are advices - default setting is 192MB). Single unit of task execution is complete network, i.e. it is typically executed from start to end on only one EVE or DSP, but we can start one network with its own output in one EVE, and in parallel same or different network with its own input on second EVE.
- Same TIDL API based application code can run on EVE or DSP accelerator
This can be achieved just by modifying a device type parameter More details in Introduction to Programming Model
- Certain networks could be split between EVE and DSP
For certain networks (JDetNet is one example), it is beneficial to use concept of layer groups. One layer group runs on EVE and another on DSP. There are few layers which runs faster on DSP: SoftMax, Flatten and Concat layers. So in this case we are using DSP+EVE for single network.
3.14.2. Examples and Demos¶
3.14.2.1. TIDL API examples¶
This TIDL release comes with 5 examples provided in source, that can be cross-compiled on Linux x86 from top level Makefile (use tidl-examples as target), or on target file-system in: /usr/share/ti/tidl/examples (make).
| Example | Link |
|---|---|
| Imagenet Classification | Image classification |
| Segmentation | Pixel segmentation |
| SSD_multibox | Single shot Multi-box Detection |
| test | Unit test |
| Classification with class filtering | tidl-matrix-gui-demo |
3.14.2.2. Matrix GUI demo¶
Upon boot, Matrix-GUI is started with multiple button that can start many demos. In current release, PLSDK 5.0, there is sub-menu “TI Deep Learning” with three buttons:
- ImageNet classification using Jacinto11 model with pre-recorded real-world video clip.
- ImageNet classification using Jacinto11 model with pre-recorded video clip, synthetically created from several static video images (using ImageMagick convert tool)
- ImageNet classification using Jacinto11 model with live camera input.
Imagenet classification using Jacinto11 model https://github.com/tidsp/caffe-jacinto-models/tree/caffe-0.17/trained/image_classification/imagenet_jacintonet11v2/sparse, with video input coming from pre-recorded clip. It is decoded in real-time via GStreamer pipeline (involving IVAHD), and sent to OpenCV processing pipeline. Live camera input (default 640x480 resolution), or decoded video clip (320x320 resolution), are scaled down and central-cropped in run-time (using OpenCV API) to 224x224 before sending to TIDL API. Result of this processing is standard Imagenet classification output (1D vector with 1000 elements). Further there is provision to define subset of objects expected to be present in video clip or live camera input, so classification results. This allows additional decision filtering (by using list of classes provided as command line argument). Blue bounding rectangle (in main image window) is presented only when valid detection is reported. Class string of last successful is preserved until next detection (so if no object is detected, blue rectangle will disappear, but last class string remains).
Executable invoked from Matrix-GUI is in: /usr/share/ti/tidl/examples/tidl_classification.
root@am57xx-evm:/usr/share/ti/tidl/examples/classification# ./tidl_classification -h
Usage: tidl
Will run all available networks if tidl is invoked without any arguments.
Use -c to run a single network.
Optional arguments:
-c Path to the configuration file
-n <number of cores> Number of cores to use (1 - 4)
-t <d|e> Type of core. d -> DSP, e -> EVE
-l List of label strings (of all classes in model)
-s List of strings with selected classes
-i Video input (for camera:0,1 or video clip)
-v Verbose output during execution
-h Help
Here is an example (invoked from /usr/share/ti/tidl/examples/classification folder), of classification using live camera input - stop at any time with mouse right-click on main image window:
cd /usr/share/ti/tidl/examples/classification
./tidl_classification -n 2 -t d -l ./imagenet.txt -s ./classlist.txt -i 1 -c ./stream_config_j11_v2.txt
Another example (invoked from /usr/share/ti/tidl/examples/classification folder), of classification using pre-recorded video input (test2.mp4) - stop at any time with mouse right-click on main image window: Please note that video clip is looped as long as maximum frame count (specified in stream_config_j11_v2.txt) is not exceeded.
cd /usr/share/ti/tidl/examples/classification
./tidl_classification -n 2 -t d -l ./imagenet.txt -s ./classlist.txt -i ./clips/test2.mp4 -c ./stream_config_j11_v2.txt
On AM5749, above two examples can be run on EVE as well, by changing “-t” parameter from “d” to “e”:
cd /usr/share/ti/tidl/examples/classification
./tidl_classification -n 2 -t e -l ./imagenet.txt -s ./classlist.txt -i 1 -c ./stream_config_j11_v2.txt
./tidl_classification -n 2 -t e -l ./imagenet.txt -s ./classlist.txt -i ./clips/test2.mp4 -c ./stream_config_j11_v2.txt
Please note that imagenet.txt is list of all classes (labels) that can be detected by the model specified in configuration file (stream_config_j11_v2.txt). List of filtered (allowed) detections is specified in ./classlist.txt (using subset of strings from imagenet.txt). E.g. currently following subset is used:
- coffee_mug
- coffeepot
- tennis_ball
- baseball
- sunglass
- sunglasses
- water_bottle
- pill_bottle
- beer_glass
- fountain_pen
- laptop
- notebook
Different group of classes using different inputs can be used for user defined testing. In that case, download square images (if aspect is not square, do central cropping first) and place in folder on Linux x86 (that has ImageMagick and ffmpeg installed). Following commands should be executed to create synthetic video clip that can be used in classification example:
# Linux x86 commands to create short video clip out of several static images that are morphed into each other
convert ./*.jpg -delay 500 -morph 300 -scale 320x320 %05d.jpg
ffmpeg -i %05d.jpg -vcodec libx264 -profile:v main -pix_fmt yuv420p -r 15 test.mp4
If video clip is captured or prepared externally (e.g. with the smartphone), object need to be centrally located (in run-time we do resize and central cropping). Then, it should be copied to /usr/share/ti/tidl/examples/classification/clips/ (or just overwrite test1.mp4 in that same folder).
3.14.2.2.1. Description of Matrix-GUI example¶
Example is based on “imagenet” and “test” examples, with few additions related to decision filtering and visualization. There are two source files only:

- main.cpp
- Parse command line arguments (ParseArgs) and show help how to use the program (DisplayHelp)
- Initialize configuration (using network model) and executors (DSPs or EVEs), as well as execution objects (frame input and output buffers).
- Create windows with TIDL static image, Decoded clip or Live camera input and window with the list of enabled classes.
- Main processing loop is in RunConfiguration
- Additional functions: tf_postprocess (sort detections and check if top candidate is enabled in the subset) and ShowRegion (if decision is stable for last 3 frames).
- findclasses.cpp
- Function populate_labels(), which reads all the model labels (E.g. 1000 strings for 1000-class imagenet classification model)
- Function populate_selected_items(), which reads and verifies label names (using previous list of valid values), to be used in decision filtering.
3.14.3. Developer’s guide¶
3.14.3.1. Software Stack¶
Complexity of software is provided for better understanding only. It is expected that the user does programming based on TIDL API only.
In case TIDL uses DSP as accelerator there are three software layers:
- TIDL Library that runs on DSP C66
- OpenCL run-time, which runs on A15, and DSP
- TIDL API host wrapper, user space library
In case TIDL uses EVE as accelerator there are four software layers:
- TIDL Library that runs on EVE
- M4 service layer, acting as proxy between EVE and A15 Linux (considered to be part of OpenCL)
- OpenCL run-time, which runs on A15, but also on M4 (IPU1 which is reserved for TIDL OpenCL monitor role)
- TIDL API host wrapper, user space library
Please note that TIDL API package APIs are identical whether we use DSP or EVE (or both). User only needs to specify accelerator via parameter.
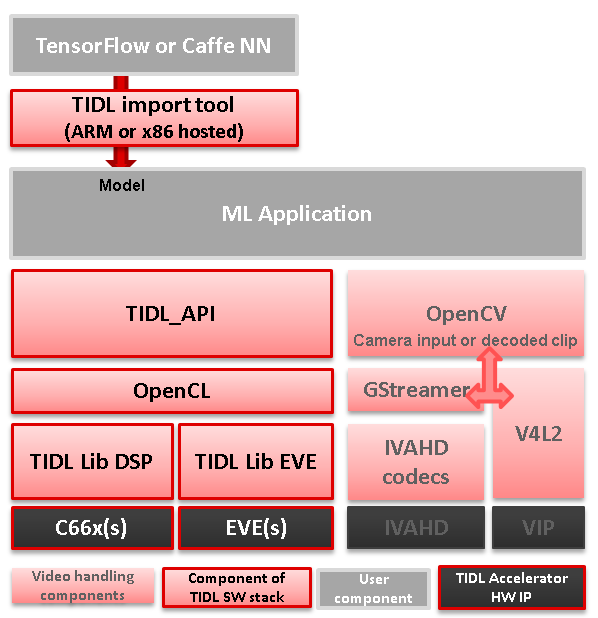
Fig. 3.7 Figure TIDL Software Stack
3.14.3.2. Additional public TI resources¶
Following two Caffe-related repositories (maintained by TI team) provides necessary tools for the training phase. Please use them as primary source of information for training, for TIDL inference software. They include modifications in Caffe source tree to enable higher compute performance (with TIDL inference).
| Repo/URL | Description |
|---|---|
| Caffe-jacinto | fork of NVIDIA/caffe, which in-turn is derived from BVLC/Caffe. The modifications in this fork enable training of sparse, quantized CNN models - resulting in low complexity models that can be used in embedded platforms. Please follow README.md, how to clone, compile and install this version of Caffe. |
| Caffe-jacinto-models | provides example scripts for training sparse models using tidsp/caffe-jacinto. These scripts enable training of sparse CNN models resulting in low complexity models that can be used in embedded platforms. This repository also includes pre-trained models. Additional scripts that can be used to prepare data set and run the training are also available in the scripts folder. |
3.14.3.3. Introduction to Programming Model¶
Public TIDL API interface is described in details at https://software-dl.ti.com/mctools/esd/docs/tidl-api/intro.html
In current release it has 3 classes only, allowing use of one or multiple neural network models that can run in parallel on independent EVEs or C66x cores.
Single unit of processing is a tensor (e.g. one image frame, but other inputs are also possible), which is typically processed by single accelerator (EVE or DSP), till completion. But in certain cases it is justified, from performance point of view, to split network layers into two layer groups. Than, we can have one layer group running on EVE and second layer group on DSP. This is done sequentially.
Top layer TIDL API and OpenCL are primarily service software layers (with respect to TIDL software, not NN), i.e. they help in simplifying programming model, IPC mechanism and memory management. Desired features are provided by TIDL Lib which runs in RTOS environment, either on EVE or DSP. This software layer is provided in closed firmware, and used as is, by end user.
3.14.3.4. Target file-system¶
3.14.3.4.1. Firmware¶
OpenCL firmware includes pre-canned DSP TIDL Lib (with hard-coded kernels) and EVE TIDL Lib following Custom Accelerator model. OpenCL firmware is downloaded to DSP and M4/EVE immediately after Linux boot:
- dra7-ipu1-fw.xem4 -> /lib/firmware/dra7-ipu1-fw.xem4.opencl-monitor
- dra7-dsp1-fw.xe66 -> /lib/firmware/dra7-dsp1-fw.xe66.opencl-monitor
- dra7-dsp2-fw.xe66 -> /lib/firmware/dra7-dsp2-fw.xe66.opencl-monitor
3.14.3.4.2. User space components¶
User space TIDL components are included in the Folder /usr/share/ti/tidl and its sub-folders. The sub-folder name and description is as follows:
| Sub folder | Description of content |
|---|---|
| examples | test (file-to-file examples), imagenet classification, image segmentation and SSD multibox examples are here. Matrix GUI example which is based on imagenet one, is in folder tidl_classification. |
| utils | ARM 32-bit binaries for importing models and simulation, and configuration files for running example import tool operations. |
| viewer | Imported model parser and dot graph creator. Input is TIDL model, output is .dot file that can be converted to PNG or PDF format using dot utility (on x86). |
| tidl_api | Source of TIDL API implementation. |
3.14.3.5. Input data format¶
Current release is mainly used with 2D inputs. Most frequent 2D input tensors are color images. Format has to be prepared in same like it was used during model training. Typically, this is following BGR plane interlaced format (common in OpenCV). That means, first 2D array is Blue color plane, next is Green color plane and finally Red color plane.
But, it is perfectly possible to have E.g. two planes on input only: E.g. one plane with Lidar distance measurements and second plane with illumination. This assumes that same format was used during training.
3.14.3.6. Output data format¶
- Image classification
There is 1D vector at the output, one byte per class (log(softmax)). If model has 100 classes, output buffer will 100 bytes long, if model has 1000 classes, output buffer will be 1000 bytes long
- Image segmentation
Output buffer is 2D buffer, typically WxH (Width and Height of input image). Each byte is class index of pixel in input image. Typically count of classes is one or two dozens (but has to be fewer than 255).
- Object detection
Output buffer is a list of tuples including: class index, bounding box (4 parameters) and optionally probability metric.
3.14.3.7. Import Process¶
Import process is done in two steps.
- The first step deals with parsing of model parameters and network topology, and converting them into custom format that TIDL Lib can understand.
- The second step does calibration of dynamic quantization process by finding out ranges of activations for each layer. This is accomplished by invoking simulation (using native C implementation) which estimates initial values important for quantization process. These values are later updated on per frame basis, assuming strong temporal correlation between input frames.
During import process, some of layers will be coalesced into one TIDL Layer (e.g. convolution and ReLU layer). This is done to further leverage EVE architecture which allows certain operations for free. Structure of converted (but equivalent) network can be checked using TIDL network viewer.
We provide a tool (Linux x86 or ARM Linux port) to import the Model and Parameters trained using either caffe frame work or tensor flow frame work in PC. This tool will accept various parameters through import configuration file and generate the Model and Parameter file that the code will be executed using TIDL library across multiple EVE and DSP cores. The import configuration file is available in {TIDL_install_path}/test/testvecs/config/import
Sample Usage: tidl_model_import.out ./test/testvecs/config/import/tidl_import_jseg21.txt
The list of import configuration parameters is as below:
| Parameter | Configuration |
|---|---|
| randParams | can be either 0 or 1. Default value is 0. If it is set to 0, the tool will generate the quantization parameters from model, otherwise it will generate random quantization parameters |
| modelType | can be either 0 or 1. Default value is 0. Set this to 0 to read from caffeImport frame work, and set it to 1 to read from tensor flow frame work. |
| quantizationStyle | can be ‘0’ for fixed quantization by the training framework or ‘1’ for dynamic quantization by. Default value is 1. Currently, only dynamic quantization is supported |
| quantRoundAdd | can take any value from 0 to 100. Default value is 50. quantRoundAdd/100 will be added while rounding to integer |
| numParamBits | can take values from 4 to 12. Default value is 8. This is the number of bits used to quantize the parameters |
| preProcType | can take values from 0 to 3. Default value is 0. |
| Conv2dKernelType | can be either 0 or 1 for each layer. Default value is 0 for all the layers. Set it to 0 to use sparse convolution, otherwise, set it to 1 to use dense convolution |
| inElementType | can be either 0 or 1. Default value is 1. Set it to 0 for 8-bit unsigned input or to 1 for 8-bit signed input |
| inQuantFactor | can take values >0. Default value is -1 |
| rawSampleInData | can be either 0 or 1. Default value is 0. Set it to 0, if the input data is encoded, or set it to 1, if the input is RAW data. |
| numSampleInData | can be > 0. Default value is 1. |
| foldBnInConv2D | can be either 0 or 1. Default value is 1. |
| inWidth | is Width of the input image, it can be >0. |
| inHeight | is Height of the input image, it can be >0 |
| inNumChannels | is input number of channels. It can be from 1 to 1024 |
| sampleInData | is Input data File name |
| tidlStatsTool | is TIDL reference executable |
| inputNetFile | is Input net file name (From Training frame work) |
| inputParamsFile | is Input Params file name (From Training frame work) |
| outputNetFile | is Output Model net file name, to be updated with stats. |
| outputParamsFile | is Output Params file name |
| layersGroupId | indicates group of layers that needs to be processed on a given CORE. Refer SSD import config for example usage |
3.14.3.7.1. Example of import config files¶
Command to convert model (specified in configuration file)
./tidl_model_import.out ./import/tidl_import_j11_v2.txt
3.14.3.7.2. Sample configuration file (tidl_import_j11_v2.txt)¶
# Default - 0
randParams = 0
# 0: Caffe, 1: TensorFlow, Default - 0
modelType = 0
# 0: Fixed quantization By tarininng Framework, 1: Dynamic quantization by TIDL, Default - 1
quantizationStyle = 1
# quantRoundAdd/100 will be added while rounding to integer, Default - 50
quantRoundAdd = 50
# 0 : 8bit Unsigned, 1 : 8bit Signed Default - 1
inElementType = 0
rawSampleInData = 1
# Fold Batch Normalization Layer into TIDL Lib Conv Layer
foldBnInConv2D = 1
# Weights are quantized into this many bits:
numParamBits = 12
# Specify sparse of dense
Conv2dKernelType = 1
# Network topology definition file
inputNetFile = "import/dogs_deploy.prototxt"
# Parameter file
inputParamsFile = "import/DOGS_iter_34000.caffemodel"
# Translated network stored into two files:
outputNetFile = "tidl_net_imagenet_jacintonet11v2.bin"
outputParamsFile = "tidl_param_imagenet_jacintonet11v2.bin"
# Calibration image file
sampleInData = "import/test.raw"
# Reference implementation executable, used in calibration (processes calibration image file)
tidlStatsTool = "import/eve_test_dl_algo_ref.out"
3.14.3.7.3. Import tool traces¶
During conversion, import tool generates traces reporting detected layers and its parameters (last several columns indicate input tensor dimensions and output tensor dimensions).
Processing config file ./tempDir/qunat_stats_config.txt !
0, TIDL_DataLayer , 0, -1 , 1 , x , x , x , x , x , x , x , x , 0 , 0 , 0 , 0 , 0 , 1 , 3 , 224 , 224 ,
1, TIDL_BatchNormLayer , 1, 1 , 1 , 0 , x , x , x , x , x , x , x , 1 , 1 , 3 , 224 , 224 , 1 , 3 , 224 , 224 ,
2, TIDL_ConvolutionLayer , 1, 1 , 1 , 1 , x , x , x , x , x , x , x , 2 , 1 , 3 , 224 , 224 , 1 , 32 , 112 , 112 ,
3, TIDL_ConvolutionLayer , 1, 1 , 1 , 2 , x , x , x , x , x , x , x , 3 , 1 , 32 , 112 , 112 , 1 , 32 , 56 , 56 ,
4, TIDL_ConvolutionLayer , 1, 1 , 1 , 3 , x , x , x , x , x , x , x , 4 , 1 , 32 , 56 , 56 , 1 , 64 , 56 , 56 ,
5, TIDL_ConvolutionLayer , 1, 1 , 1 , 4 , x , x , x , x , x , x , x , 5 , 1 , 64 , 56 , 56 , 1 , 64 , 28 , 28 ,
6, TIDL_ConvolutionLayer , 1, 1 , 1 , 5 , x , x , x , x , x , x , x , 6 , 1 , 64 , 28 , 28 , 1 , 128 , 28 , 28 ,
7, TIDL_ConvolutionLayer , 1, 1 , 1 , 6 , x , x , x , x , x , x , x , 7 , 1 , 128 , 28 , 28 , 1 , 128 , 14 , 14 ,
8, TIDL_ConvolutionLayer , 1, 1 , 1 , 7 , x , x , x , x , x , x , x , 8 , 1 , 128 , 14 , 14 , 1 , 256 , 14 , 14 ,
9, TIDL_ConvolutionLayer , 1, 1 , 1 , 8 , x , x , x , x , x , x , x , 9 , 1 , 256 , 14 , 14 , 1 , 256 , 7 , 7 ,
10, TIDL_ConvolutionLayer , 1, 1 , 1 , 9 , x , x , x , x , x , x , x , 10 , 1 , 256 , 7 , 7 , 1 , 512 , 7 , 7 ,
11, TIDL_ConvolutionLayer , 1, 1 , 1 , 10 , x , x , x , x , x , x , x , 11 , 1 , 512 , 7 , 7 , 1 , 512 , 7 , 7 ,
12, TIDL_PoolingLayer , 1, 1 , 1 , 11 , x , x , x , x , x , x , x , 12 , 1 , 512 , 7 , 7 , 1 , 1 , 1 , 512 ,
13, TIDL_InnerProductLayer , 1, 1 , 1 , 12 , x , x , x , x , x , x , x , 13 , 1 , 1 , 1 , 512 , 1 , 1 , 1 , 9 ,
14, TIDL_SoftMaxLayer , 1, 1 , 1 , 13 , x , x , x , x , x , x , x , 14 , 1 , 1 , 1 , 9 , 1 , 1 , 1 , 9 ,
15, TIDL_DataLayer , 0, 1 , -1 , 14 , x , x , x , x , x , x , x , 0 , 1 , 1 , 1 , 9 , 0 , 0 , 0 , 0 ,
Layer ID ,inBlkWidth ,inBlkHeight ,inBlkPitch ,outBlkWidth ,outBlkHeight,outBlkPitch ,numInChs ,numOutChs ,numProcInChs,numLclInChs ,numLclOutChs,numProcItrs ,numAccItrs ,numHorBlock ,numVerBlock ,inBlkChPitch,outBlkChPitc,alignOrNot
2 72 64 72 32 28 32 3 32 3 1 8 1 3 4 4 4608 896 1
3 40 30 40 32 28 32 8 8 8 4 8 1 2 4 4 1200 896 1
4 40 30 40 32 28 32 32 64 32 7 8 1 5 2 2 1200 896 1
5 40 30 40 32 28 32 16 16 16 7 8 1 3 2 2 1200 896 1
6 40 30 40 32 28 32 64 128 64 7 8 1 10 1 1 1200 896 1
7 40 30 40 32 28 32 32 32 32 7 8 1 5 1 1 1200 896 1
8 24 16 24 16 14 16 128 256 128 8 8 1 16 1 1 384 224 1
9 24 16 24 16 14 16 64 64 64 8 8 1 8 1 1 384 224 1
10 24 9 24 16 7 16 256 512 256 8 8 1 32 1 1 216 112 1
11 24 9 24 16 7 16 128 128 128 8 8 1 16 1 1 216 112 1
Processing Frame Number : 0
Final output (based on calibration raw image as provided in configuration file), is stored in a file with reserved name: stats_tool_out.bin Size of this file should be identical to count of output classes (in case of classification). E.g. for imagenet 1000 classes, it has to be 1000 bytes big. In addition to final blob, all intermediate results (activations of individual layers), are stored in ./tempDir folder (inside folder where import is invoked). Here is a sample list of files with intermediate activations:
- trace_dump_0_224x224.y <- This very first layer should be identical to the data blob used in desktop Caffe (during validation)
- trace_dump_1_224x224.y
- trace_dump_2_112x112.y
- trace_dump_3_56x56.y
- trace_dump_4_56x56.y
- trace_dump_5_28x28.y
- trace_dump_6_28x28.y
- trace_dump_7_14x14.y
- trace_dump_8_14x14.y
- trace_dump_9_7x7.y
- trace_dump_10_7x7.y
- trace_dump_11_7x7.y
- trace_dump_12_512x1.y
- trace_dump_13_9x1.y
- trace_dump_14_9x1.y
3.14.3.7.4. Splitting layers between layers groups¶
In order to use both DSP and EVE accelerators, it is possible to split the network into two sub-graphs using concept of layergroups. Than one layer group can be executed on EVE and another on DSP. Output of first group (running on EVE) will be used as input for DSP.
This can be accomplished in following way (providing an example for Jacinto11 network):
# Default - 0
randParams = 0
# 0: Caffe, 1: TensorFlow, Default - 0
modelType = 0
# 0: Fixed quantization By tarininng Framework, 1: Dynamic quantization by TIDL, Default - 1
quantizationStyle = 1
# quantRoundAdd/100 will be added while rounding to integer, Default - 50
quantRoundAdd = 25
numParamBits = 8
# 0 : 8bit Unsigned, 1 : 8bit Signed Default - 1
inElementType = 0
inputNetFile = "../caffe_jacinto_models/trained/image_classification/imagenet_jacintonet11v2/sparse/deploy.prototxt"
inputParamsFile = "../caffe_jacinto_models/trained/image_classification/imagenet_jacintonet11v2/sparse/imagenet_jacintonet11v2_iter_160000.caffemodel"
outputNetFile = "./tidl_models/tidl_net_imagenet_jacintonet11v2.bin"
outputParamsFile = "./tidl_models/tidl_param_imagenet_jacintonet11v2.bin"
sampleInData = "./input/preproc_0_224x224.y"
tidlStatsTool = "./bin/eve_test_dl_algo_ref.out"
layersGroupId = 0 1 1 1 1 1 1 1 1 1 1 1 2 2 2 0
conv2dKernelType = 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1
Input and output layer belong to layer group 0. Layergroup 1 is dispatched to EVE, and layergroup 2 to DSP.
Second row (conv2dKernelType) indicates if computation is sparse (0) or dense (1).
After conversion, we can visualize the network:
tidl_viewer -p -d ./j11split.dot ./tidl_net_imagenet_jacintonet11v2.bin
dot -Tpdf ./j11split.dot -o ./j11split.pdf
Here is a graph (group 1 is executed on EVE, and group 2 is executed on DSP):

Output of layers group 1 is shared (common) with input buffer of layers group 2 so no extra buffer copy overhead. Due to this buffer allocation, sequential operation of EVE and DSP is necessary.
3.14.3.7.5. Calculating theoretical GMACs needed¶
This can be calculated for up-front for computationally most intensive layers: Convolution Layers and Fully Connected Layers. Each Convolution Layer has certain number of input and output feature maps (2D tensors). Input feature map is convolved with convolution kernel (usually 3x3, but also 5x5, 7x7..). So total number of MACs can be calculated as: Height_input_map x Width_input_map x N_input_maps x N_output_maps x size_of_kernel.
E.g. for 112x112 feature map, with 64 inputs, 64 outputs and 3x3 kernels, we need:
112x112x64x64x3x3 MAC operations = 4624229916 MAC operations
Similarly for fully connected layer, with N_inputs and N_outputs, total number of MAC operations is
E.g. N_inputs = 4096 and N_outputs = 1000,
Fully Connected Layer MAC operations = N_inputs * N_outputs = 4096 * 1000 = 4096000 MAC operations
Obviously Convolution Layer workload is significantly higher.
3.14.3.7.6. Mapping to EVE capabilities¶
Each EVE core can do 16 MAC operation per cycle. Accumulated results are stored in 40-bit accumulator and can be barrel shifted before stored into local memory. Also, EVE can do ReLU operation for free, so frequently, Convolution Layer or Fully Connected Layer is coalesced with ReLU layer.
In order to support these operations wide path to local memory is needed. Concurrently transfers from external DDR memory are performed using dedicated EDMA engines. So, when EVE does convolutions it is always accessing both activations and weights that are already present in high speed local memory.
One or two layers are implemented on EVE local RISC CPU which is used primarily for programming vector engine and EDMA. In these rare cases EVE CPU is used as fully programmable, but slow compute engine. SoftMax layer is implemented using general purpose CPU, and significantly slower than DSP or A15 implementation. As SoftMax layer is terminal layer it is advised to do SoftMax either on A15 (in user space) or using DSP (layergroup2, as implemented in JDetNet examples).
3.14.3.8. Viewer tool¶
Viewer tool does visualization of imported network model. More details available at https://software-dl.ti.com/mctools/esd/docs/tidl-api/viewer.html Here is an example command line:
root@am57xx-evm:/usr/share/ti/tidl/examples/test/testvecs/config/tidl_models# tidl_viewer
Usage: tidl_viewer -d <dot file name> <network binary file>
Version: 01.00.00.02.7b65cbb
Options:
-p Print network layer info
-h Display this help message
root@am57xx-evm:/usr/share/ti/tidl/examples/test/testvecs/config/tidl_models# tidl_viewer -p -d ./jacinto11.dot ./tidl_net_imagenet_jacintonet11v2.bin
# Name gId #i #o i0 i1 i2 i3 i4 i5 i6 i7 o #roi #ch h w #roi #ch h w
0, Data , 0, -1 , 1 , x , x , x , x , x , x , x , x , 0 , 0 , 0 , 0 , 0 , 1 , 3 , 224 , 224 ,
1, BatchNorm , 1, 1 , 1 , 0 , x , x , x , x , x , x , x , 1 , 1 , 3 , 224 , 224 , 1 , 3 , 224 , 224 ,
2, Convolution , 1, 1 , 1 , 1 , x , x , x , x , x , x , x , 2 , 1 , 3 , 224 , 224 , 1 , 32 , 112 , 112 ,
3, Convolution , 1, 1 , 1 , 2 , x , x , x , x , x , x , x , 3 , 1 , 32 , 112 , 112 , 1 , 32 , 56 , 56 ,
4, Convolution , 1, 1 , 1 , 3 , x , x , x , x , x , x , x , 4 , 1 , 32 , 56 , 56 , 1 , 64 , 56 , 56 ,
5, Convolution , 1, 1 , 1 , 4 , x , x , x , x , x , x , x , 5 , 1 , 64 , 56 , 56 , 1 , 64 , 28 , 28 ,
6, Convolution , 1, 1 , 1 , 5 , x , x , x , x , x , x , x , 6 , 1 , 64 , 28 , 28 , 1 , 128 , 28 , 28 ,
7, Convolution , 1, 1 , 1 , 6 , x , x , x , x , x , x , x , 7 , 1 , 128 , 28 , 28 , 1 , 128 , 14 , 14 ,
8, Convolution , 1, 1 , 1 , 7 , x , x , x , x , x , x , x , 8 , 1 , 128 , 14 , 14 , 1 , 256 , 14 , 14 ,
9, Convolution , 1, 1 , 1 , 8 , x , x , x , x , x , x , x , 9 , 1 , 256 , 14 , 14 , 1 , 256 , 7 , 7 ,
10, Convolution , 1, 1 , 1 , 9 , x , x , x , x , x , x , x , 10 , 1 , 256 , 7 , 7 , 1 , 512 , 7 , 7 ,
11, Convolution , 1, 1 , 1 , 10 , x , x , x , x , x , x , x , 11 , 1 , 512 , 7 , 7 , 1 , 512 , 7 , 7 ,
12, Pooling , 1, 1 , 1 , 11 , x , x , x , x , x , x , x , 12 , 1 , 512 , 7 , 7 , 1 , 1 , 1 , 512 ,
13, InnerProduct , 1, 1 , 1 , 12 , x , x , x , x , x , x , x , 13 , 1 , 1 , 1 , 512 , 1 , 1 , 1 , 1000 ,
14, SoftMax , 1, 1 , 1 , 13 , x , x , x , x , x , x , x , 14 , 1 , 1 , 1 , 1000 , 1 , 1 , 1 , 1000 ,
15, Data , 0, 1 , -1 , 14 , x , x , x , x , x , x , x , 0 , 1 , 1 , 1 , 1000 , 0 , 0 , 0 , 0 ,
Output file is jacinto11.dot, that can be converted to PNG or PDF file on Linux x86, using (E.g.):
dot -Tpdf ./jacinto11.dot -o ./jacinto11.pdf
- Point to layer groups in JDetNet and describe how to do graph partitioning into two groups, creating EVE optimal group and DSP optimal group
3.14.3.9. Simulation Tool¶
We provide simulation tool both in PLSDK ARM filesystem, and Linux x86 simulation tool. This is bit-exact simulation, so output of simulation tool is expected to be identical to the output of A5749 or AM57xx target. Please use this tool as convenience tool only (E.g. testing model on setup without target EVM).
Simulation tool can be used also to verify converted model accuracy (FP32 vs 8-bit implementation). It can run in parallel on x86 leveraging bigger number of cores (simulation tool is single thread implementation). Due to bit-exact simulation, performance of simulation tool cannot be used to predict target execution time, but it can used to validate model accuracy.
An example of configuration file, which includes specification of frame count to process, input image file (with one or more raw images), numerical format of input image file (signed or unsigned), trace folder and model files:
rawImage = 1
numFrames = 1
inData = "./tmp.raw"
inElementType = 0
traceDumpBaseName = "./out/trace_dump_"
outData = "stats_tool_out.bin"
netBinFile = "./tidl_net_imagenet_jacintonet11v2.bin"
paramsBinFile = "./tidl_param_imagenet_jacintonet11v2.bin"
In case multiple images need to be processed, below (or similar) script can be used:
SRC_DIR=$1
echo "#########################################################" > TestResults.log
echo "Testing in $SRC_DIR" >> TestResults.log
echo "#########################################################" >> TestResults.log
for filename in $SRC_DIR/*.png; do
convert $filename -separate +channel -swap 0,2 -combine -colorspace sRGB ./sample_bgr.png
convert ./sample_bgr.png -interlace plane BGR:sample_img_256x256.raw
./eve_test_dl_algo.out sim.txt
echo "$filename Results " >> TestResults.log
hd stats_tool_out.bin | tee -a TestResults.log
done
Simulation tool ./eve_test_dl_algo.out is invoked with single command line argument:
./eve_test_dl_algo.out sim.txt
Simulation configuration file includes list of network modesl to execute, in this case only one: tild_config_j11.txt List is termined with: “0 ”:
1 ./tidl_config_j11_v2.txt
0
Sample confiuguration file used by simulation tool (tidl_config_j11_v2.txt):
rawImage = 1
numFrames = 1
preProcType = 0
inData = "./sample_img_256x256.raw"
traceDumpBaseName = "./out/trace_dump_"
outData = "stats_tool_out.bin"
updateNetWithStats = 0
netBinFile = "./tidl_net_model.bin"
paramsBinFile = "./tidl_param_model.bin"
Results for all images in SRC_DIR will be directed to TestResults.log, and can be tested against Caffe-Jacinto desktop execution.
3.14.3.10. Summary of model porting steps¶
- After model creation using desktop framework (Caffe or TF), it is ncessary to verify accuracy of the model (using inference on desktop framework: Caffe/Caffe-Jacinto or TensorFlow).
- Import the final model (in case of Caffe-Jacinto, at the end of “sparse” phase) using above import procedure
- Verify accuracy (using smaller test data set than the one used in first step) using simulation tool. - Drop in accuracy (vs first step) should not be big (few percents).
- Test the network on the target, using TIDL API based program and imported model.
3.14.4. Training¶
Existing Caffe and TF-Slim models can be imported as long as layers are supported and parameter constraints are met. But, typically these models include dense weight matrices. In order to leverage some benefits of TIDL Lib, and gain 3x-4x performance improvement (for Convolution Layers), it is necessary to repeat the training process using caffe-jacinto caffe fork, available at https://github.com/tidsp/caffe-jacinto Highest contribution to Convolution Neural Networks compute load comes from Convolution Layers (often in 80-90% range), hence special attention is paid to optimize Convolution Layer processing.
Data set preparation should follow standard Caffe approach, typically creating LMDB files. After that training is done in 3 steps:
- Initial training (typically with L2 regularization), creating dense model.
This phase is actually usual training procedure applied on desktop. At the end of this phase, it is necessary to verify accuracy of the model. Weight tensors are dense so performance target may not be hit but following steps can improve the performance. If accuracy is not sufficient, it is not advisible to proceed with further steps (they won’t improve accuracy - actually small drop in accruacy of 1-2% is expected). Instead, modify training parameters or enhance data set, and repeat the training, until accuracy target is met.
- L1 regularization
This step is necessary to (opposite to L2) favor certain weight values at the expense of others, and make larger portion weights smaller. Remaining weights would behave like feature extractors (required for next step).
- Sparse (“sparsification”)
By gradual adjustment of weight threshold (from smaller to higher) sparsification target is tested at each step (E.g. 70% or 80%). This procedure eliminates small weights, leaving bigger contributors only. Please note that this applies to Convolution Layers only.
- Define acceptable criteria for sparsification based on accuracy drop
Due to conversion from FP32 representation to 8-12 bit representation of weights (and 8-bit activations), acceptable accuracy drop should be within 1-2% range (depending on model), E.g. if classification accuracy for Caffe-Jacinto desktop model is 70% (using model after initial phase), we should not see lower accuracy for sparsified and quantized model below 68%.
3.14.4.1. Example of training procedure¶
- Setup for data set collection of specific smaller objects.
Apart from many publicly available image data sets, it is frequently the case that new data set need to be collected for specific use case. E.g. in industrial environment, is typically more predictable and often it is possible to ensure controlled environment with good illumination. For pick-and-place applications, set of objects that can appear in camera field-of-view is not infinite, but rather confined to few or few dozens classes. Using turn-table and photo booth with good illumination allows quick data set collection.
- Data set collection using AM57xx
Data set images can be recorded by external camera device, or even using Camera Daughter card (of AM57xx). Suggested recorded format is H264, that offers good quality and can be efficiently decoded using GStreamer pipeline. It can last 15-20 seconds only (rotation period of turn-table). With slower fps (10-15fps), this provides 200-300 frames. Procedure can be repeated by changing distance and elevation (3-4 times), so total image count can be up to 2000-3000 frames per class. This can limit single class data collection time to 5-10min.
- Post-processing
Video clips should be copied to Linux x86 for offline post-processing. FFMPEG package allows easy splitting of video clips into individual images. Since recording is made against uniform background, it is also possible to apply automated labeling procedure. Additional data set enhancements can be made using image augmentation scripts, easily increasing count of images 10-20x.
- Prepare LMDB files for the training
Please refer to available scripts in github.com/tidsp/caffe-jacinto-models/scripts
- Do training from scratch or do transfer learning (fine-tuning)
Frequently, it is good to start training using initial weights created with generic data set (like ImageNet). Bottom layers act like feature extractors, and only top 1 or few layers need to be fine tuned using data set that we just collected (as described in previous sets). In case of Jacinto11, good starting point is model created after “Initial” phase. We will need to repeat initial phase, but now using new data set, and using same layer names for those layers that we want to pre-load with earlier model. Further, training can be tuned by reducing base_lr (in train.prototxt), and increasing lr for top one or few layers. In this way bottom layers will be changed superficially, but top layers will adapt as necessary.
3.14.4.2. Where does the benefit of sparsification come from?¶
- Initially Deep Learning networks were implemented using Single Precision floating-point arithmetic’s (FP32). During last few years, more research has been done regarding quantization impact and reduced accuracy of arithmetic operations. In many cases, 8-bits, or even less (down to 2-4 bits) are considered sufficient for correct operation. This is explained with huge number of parameters (weights) that all contribute to operation accuracy. In case of DSP and EVE inference implementation, weights (controlled by parameter in import tool configuration file) can be quantized with 8-12 bit accuracy. Activation layer outputs (neuron output) are stored in memory with 8-bit accuracy (single byte). Accumulation is done with 40-bit accuracy, but final output is right-shifted before single byte is stored into memory. Right shift count is determined dynamically, uniquely for each layer and once per frame. More details can be found in https://openaccess.thecvf.com/content_cvpr_2017_workshops/w4/papers/Mathew_Sparse_Quantized_Full_CVPR_2017_paper.pdf
- Additional optimization (described in above article) is based on sparsification of Convolution Layer weights. Individual weights are forced to zero during training. This is achieved during “L1 regularization” phase (enforcing fewer bigger weights at the expense of others) and “Sparse” when small weights are clamped to zero. We can specify desired training target (E.g. 70% or 80% of all weights to be zero). During inference, computation is reorganized so that multiplication with single weight parameter is done across all input values. If weight is zero multiplication against all input data (for that input channel) is skipped. All computation are done using pre-loaded blocks into local L2 memory (using “shadow” EDMA transfers).
3.14.5. Performance data¶
3.14.5.1. Computation performance of verified networks¶
- J11, JSeg21, JDetNet, Mobilenet, SqueezeNet:
| Network topology | ROI size | MMAC (million MAC) | Sparsity (%) | EVE using sparse model | EVE using dense model | DSP using sparse model | DSP using dense model | EVE + DSP (optimal model) |
|---|---|---|---|---|---|---|---|---|
| MobileNet | 224x224 | 567.70 | 1.42 | 682.63ms | 717.11ms | |||
| SqueezeNet | 227x227 | 390.8 | 1.46 | 289.76ms | 1008.92ms | |||
| InceptionNetV1 | 224x224 | 1497.37 | 2.48 | 785.43ms | 2235.99ms | |||
| JacintoNet11 | 224x224 | 405.81 | 73.15 | 125.9ms | 235.70ms | 115.91ms | 370.64ms | 73.55ms |
| JSegNet21 | 1024x512 | 8506.5 | 76.47 | 378.18ms | 1236.84ms | 1101.12ms | 3825.95ms | |
| JDetNet | 768x320 | 2191.44 | 61.84 | 197.55ms |
- Sparsity provided in above table is average sparsity across all convolution layers.
- Optimal Model – with optimal placement of layers between EVE and DSP (certain NN layers run faster on DSP, like SoftMax; ARP32 in EVE emulates float operation in software, so this can be rather slow).
- Next release will have improved perforamnce by using optimal layer placement (EVE has slow SoftMax layer implementation) and will enable e.g. for Jacinto11 up to 28-30fps (on AM5749).
3.14.5.2. Accuracy of selected networks¶
Below tables are copied here for convenience, from https://github.com/tidsp/caffe-jacinto-models documents.
- Image classification : Top-1 classification accuracy indicates probability that ground truth is ranked highest. Top-5 classification accuracy indicates probability that ground truth is among top-5 ranking candidates.
| Configuration-Dataset Imagenet (1000 classes) | Top-1 accuracy |
|---|---|
| JacintoNet11 non-sparse | 60.9% |
| JacintoNet11 layerwise threshold sparse (80%) | 57.3% |
| JacintoNet11 channelwise threshold sparse (80%) | 59.7% |
- Image segmentation : Mean Intersection over Union is ratio between True Positives and sum of True Positives, False Negatives and False Positives
| Configuration-Dataset Cityscapes (5-classes) | Pixel accuracy | Mean IOU |
|---|---|---|
| Initial L2 regularized training | 96.20% | 83.23% |
| L1 regularized training | 96.32% | 83.94% |
| Sparse fine tuned (~80% zero coefficients) | 96.11% | 82.85% |
| Sparse (80%), Quantized (8-bit dynamic fixed point) | 95.91% | 82.15% |
- Object Detection : Validation accuracy can be in classification accuracy or mean average precision (mAP). Please note change in accuracy between “Initial” (dense) and “Sparse” model (performance boost can be 2x-4x):
| Configuration-Dataset VOC0712 | mAP |
|---|---|
| Initial L2 regularized training | 68.66% |
| L1 regularized fine tuning | 68.07% |
| Sparse fine tuned (~61% zero coefficients) | 65.77% |
3.14.6. Troubleshooting¶
- Validate OpenCL stack is running Upon Linux boot, OpenCL firmwares are downloaded to DSP and EVE. As OpenCL monitor for IPU1 (which controls EVEs) is new addition, here is expected trace: Enter following command on target: cat /sys/kernel/debug/remoteproc/remoteproc0/trace0 Following output is expected, indicating number of available EVE accelerators (below AM5729 trace indicates 4 EVEs):
[0][ 0.000] 17 Resource entries at 0x3000
[0][ 0.000] [t=0x000aa3b3] xdc.runtime.Main: 4 EVEs Available
[0][ 0.000] [t=0x000e54bf] xdc.runtime.Main: Creating msg queue...
[0][ 0.000] [t=0x000fb885] xdc.runtime.Main: OCL:EVEProxy:MsgQ ready
[0][ 0.000] [t=0x0010a1a1] xdc.runtime.Main: Heap for EVE ready
[0][ 0.000] [t=0x00116903] xdc.runtime.Main: Booting EVEs...
[0][ 0.000] [t=0x00abf9a9] xdc.runtime.Main: Starting BIOS...
[0][ 0.000] registering rpmsg-proto:rpmsg-proto service on 61 with HOST
[0][ 0.000] [t=0x00b23903] xdc.runtime.Main: Attaching to EVEs...
[0][ 0.007] [t=0x00bdf757] xdc.runtime.Main: EVE1 attached
[0][ 0.010] [t=0x00c7eff5] xdc.runtime.Main: EVE2 attached
[0][ 0.013] [t=0x00d1b41d] xdc.runtime.Main: EVE3 attached
[0][ 0.016] [t=0x00db9675] xdc.runtime.Main: EVE4 attached
[0][ 0.016] [t=0x00dc967f] xdc.runtime.Main: Opening MsgQ on EVEs...
[0][ 1.017] [t=0x013b958a] xdc.runtime.Main: OCL:EVE1:MsgQ opened
[0][ 2.019] [t=0x019ae01a] xdc.runtime.Main: OCL:EVE2:MsgQ opened
[0][ 3.022] [t=0x01fa62bf] xdc.runtime.Main: OCL:EVE3:MsgQ opened
[0][ 4.026] [t=0x025a4a1f] xdc.runtime.Main: OCL:EVE4:MsgQ opened
[0][ 4.026] [t=0x025b4143] xdc.runtime.Main: Pre-allocating msgs to EVEs...
[0][ 4.027] [t=0x0260edc5] xdc.runtime.Main: Done OpenCL runtime initialization. Waiting for messages...
- Please verify that CMEM is active and running:
- cat /proc/cmem
- lsmod | grep “cmem”
- Default CMEM size is not sufficient for devices with more than 2 EVEs (make ~56-64MB available per EVE).
Verify model preparation procedure
- Import process may not give enough information if it fails to import external model.
E.g. following report can be seen if format is not recognized (in this case, an attempt to import Keras model was made):
$ ./tidl_model_import.out ./modelInput/tidl_import_mymodel.txt TF Model File : ./modelInput/mymodel Num of Layer Detected : 0 Total Giga Macs : 0.0000 Processing config file ./tempDir/qunat_stats_config.txt ! 0, TIDL_DataLayer , 0, 0 , 0 , x , x , x , x , x , x , x , x , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , Processing Frame Number : 0 End of config list found !
- Data set preparation concerns
- Good lighting is very desirable while preparing training set.
- Augmentation
- Equivalence between desktop Caffe execution and target execution
For this purpose, we can use simulation tool as it is bit-exact with EVE or DSP execution. Traces that are generated by simulation tool can be visually compared against data blobs that are saved after desktop Caffe inference. If all the rest is correct, it is worth comparing intermediate results. Please keep in mind that numerical equivalence between Caffe desktop computation (using single precision FP32) and target computation (using 8-bit activations, and 8-12 bit weights) are not expected. Still features maps (of intermediate layers) are supposed to be rather similar. If something is significantly different, please try to change number of bits for weights, or repeat import processing with more representative image. Problems of this sort should be rarely encountered.
Typical errors in runtime (when to reboot the platform)
... inc/executor.h:199: T* tidl::malloc_ddr(size_t) [with T = char; size_t = unsigned int]: Assertion `val != nullptr' failed.
This means that previous run failed to de-allocate CMEM memory. Reboot is one option, restarting ti-mctd deamon is another option.