Semantic Segmentation Application¶
This demonstrates the semantic segmentation application using a deep-learning network running on J7 C7x/MMA. Figure 1 shows the high-level block diagram of the application, which consists of multiple processing blocks that are deployed on hardware accelerators and DSP processors for pre-processing and post-processing in an optimized manner.

Semantic Segmentation Model¶
A CNN model for semantic segmentation has been developed using Jacinto AI DevKit (PyTorch).
Model: deeplabv3lite_mobilenetv2_tv (for details, see LINK)
Input image: 768 x 432 pixels in RGB
Training data: Cityscapes Dataset, and a small dataset collected from ZED camera
Model compilation: TVM compilation for generating DLR model artifacts. For more details on open-source deep-learning runtime on J7/TDA4x, please check TI Edge AI Cloud.
How to Run the ROS Application¶
Run the Semantic Segmentation Demo¶
[J7] To launch ti_semseg_cnn node with playing back a ROSBAG file, run the following inside the Docker container on J7 target:
roslaunch ti_semseg_cnn bag_semseg_cnn.launch
To process the image stream from a ZED stereo camera (processing /camera/right/image_raw), replace the launch file with zed_semseg_cnn.launch:
roslaunch ti_semseg_cnn zed_semseg_cnn.launch
[Visualization on Ubuntu PC] For setting up environment of the remote PC, please follow “Set Up the Ubuntu PC for Visualization” section of docker/README.md
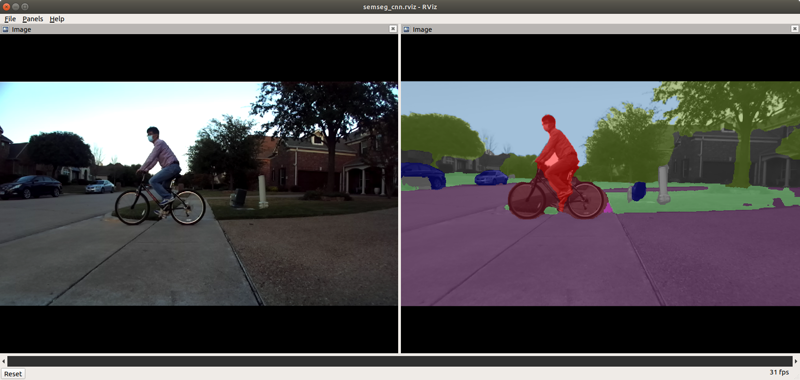
The semantic segmentation output tensor is published by the application. For visualization, a color-coded semantic segmentation image is generated. Following command launches the resulting color-mapped semantic segmentation image along with the raw image on RViz:
roslaunch ti_semseg_cnn rviz.launch
Testing Higher Input Frame Rate with ROSBAG¶
We can publish the images at higher frame rate with rosbag play --rate option. Below is an example to publish the raw images at 30 fps (double the native frame rate of the ROSBAG file).
roslaunch ti_semseg_cnn bag_semseg_cnn.launch ratefactor:=2.0
Launch File Parameters¶
| Parameter | Description | Value |
|---|---|---|
| rosparam file | Algorithm configuration parameters (see "ROSPARAM Parameters" section) | config/params.yaml |
| input_topic_name | Subscribe topic name for input camera image | camera/right/image_raw |
| rectified_image_topic | Publish topic name for output rectified image | camera/right/image_rect_mono |
| semseg_cnn_out_image | Publish topic name for semantic segmentation output image | semseg_cnn/out_image |
| output_rgb | Flag for indicating color-coded semantic segmentation map is published in RGB format | true, false |
| _ | If this flag is false, it is published in YUV420 format | _ |
| semseg_cnn_tensor_topic | Publish topic name for output semantic segmentation tensor | semseg_cnn/tensor |
ROSPARAM Parameters¶
The table below describes the parameters in config/params.yaml:
| Parameter | Description | Value |
|---|---|---|
| lut_file_path | LDC rectification table path | String |
| dlr_model_file_path | Path the DL model | String |
| width | Input image width | Integer |
| height | Input image height | Integer |
| dl_width | Image width to TIDL network | Integer |
| dl_height | Image height to TIDL network | Integer |
| out_width | Output semantic segmentation output (tensor) width | Integer |
| out_height | Output semantic segmentation output (tensor) height | Integer |
| num_classes | Number of semantic segmentation classes | 0 ~ 20 |
| enable_post_proc | Flag to indicate if the post processing of th TIDL output should be enabled | 0, 1 |
| pipeline_depth | OpenVX graph pipeline depth | 1 ~ 4 |
Processing Blocks¶
Referring to Figure 1, below are the descriptions of the processing blocks implemented in this application:
The first step to process input images with lens distortion, J7 LDC (Lens Distortion Correction) hardware accelerator (HWA) does un-distortion or rectification. Pseudo codes to create LDC tables for rectification are provided here. Note that the LDC HWA not only removes lens distortion or rectifies, but also changes image format. Input image to the application is of YUV422 (UYVY) format, which is converted to YUV420 (NV12) by the LDC.
Input images are resized to a smaller resolution, which is specified by
dl_widthanddl_heightinparams.yaml, for the semantic segmentation network. The MSC (Multi-Scaler) HWA resizes the images to a desired size.The pre-processing block, which runs on C6x, converts YUV420 (NV12) to RGB, which is expected input format for the semantic segmentation network.
The semantic segmentation network is accelerated by C7x/MMA with DLR runtime, and outputs a tensor that has class information for every pixel.
[Optional] The post-processing block, which runs on C6x, creates a color-coded semantic segmentation map image from the output tensor. It can be enabled or disabled by configuring
enable_post_procparameter inparams.yaml. Only if the post-processing block is enabled, the color-coded semantic segmentation map is created and published. Its format is YUV420. Whenoutput_rgbis true in the launch file, it is published in RGB format after conversion. If the post-processing, the semantic segmentation output tensor from the TIDL network is published instead.
Known Issue¶
The
ti_semseg_cnnsemantic segmentation CNN was trained with Cityscapes dataset first, and then re-trained with a small dataset collected from a stereo camera (ZED camera, HD mode) for a limited scenarios with coarse annotation. Therefore, the model can show limited accuracy performance if a different camera model is used and/or when it is applied in different environmental scenes.