7. Multiple Model Compilation & Inference¶
Table of Contents
This section explains how to compile and run multiple neural networks in a single inference application. Each model is compiled separately, generating multiple libraries to link with the inference application.
During inference, models can run on the host processor or the hardware NPU accelerator. Models running on the accelerator can execute concurrently with models on the host processor. However, we do not allow concurrent model execution on the hardware NPU accelerator itself.
Multiple Model Compilation & Inference benefits those who want to run various models on their devices without having to recreate or recompile their inference application.
7.1. Compilation¶
This section explains how to compile multiple models for a single inference application. Before performing these steps, follow the compilation Environment Setup.
7.1.1. Compilation Command¶
Each model is compiled separately, with two changes to the model’s individual compilation command:
Give each model a distinct name with the
--module-nameoption. Model names are case-insensitive.Give each model its own compilation artifacts directory.
tvmc compile --target="c, ti-npu" int_model_a.onnx --target-c-mcpu=c28 --module-name="a" -o artifacts_c28_a/mod_a.a --cross-compiler="cl2000" --cross-compiler-options="$(CL2000_OPTIONS)"
tvmc compile --target="c, ti-npu" int_model_b.onnx --target-c-mcpu=c28 --module-name="b" -o artifacts_c28_b/mod_b.a --cross-compiler="cl2000" --cross-compiler-options="$(CL2000_OPTIONS)"
In this two-model example, --module-name="a" and --module-name="b" specify the module names.
artifacts_c28_a/mod_a.a and artifacts_c28_b/mod_b.a specify the compilation artifacts
directories and generated libraries. You may choose different names for the modules and artifacts
directories as long as they are distinct for each model.
7.1.2. Compilation Artifacts¶
The compilation artifacts are stored in the specified directories.
Each artifacts directory for example artifacts_c28_a, contains its own model-specific files:
A header file (for example,
tvmgen_a.h)Generated C code files (for example,
lib0/lib1/lib2.c)A library file (for example,
mod_a.a)
Link all compiled model library files into your inference application.
7.2. Inference¶
This section explains how to invoke the inference functions from multiple model libraries.
7.2.1. Inference Function and Input/Output¶
The generated header file stored in the model’s artifacts directory contains the
same data structures and inference functions generated by individual model compilation. However, the
default module name has been renamed.
For example, setting a model’s --module-name="a" or --module-name="A" during compilation generates tvmgen_a.h,
which contains the following data structures and inference function:
/* Symbol defined when running model on TI NPU hardware accelerator */
#define TVMGEN_A_TI_NPU
#ifdef TVMGEN_A_TI_NPU_SOFT
#error Conflicting definition for where model should run.
#endif
/* The generated model library expects the following inputs/outputs:
* Inputs:
* Tensor[(1, 3, 128, 1), float32]
* Outputs:
* Tensor[(1, 6), float32]
* Tensor[(1, 60), float32]
*/
/* TI NPU hardware accelerator initialization */
extern void TI_NPU_init();
/* Flag for model execution completion on TI NPU hardware accelerator */
extern volatile int32_t tvmgen_a_finished;
/*!
* \brief Input tensor pointers for TVM module "a"
*/
struct tvmgen_a_inputs {
void* onnx__Add_0;
};
/*!
* \brief Output tensor pointers for TVM module "a"
*/
struct tvmgen_a_outputs {
void* output0;
void* output1;
};
/*!
* \brief entrypoint function for TVM module "a"
* \param inputs Input tensors for the module
* \param outputs Output tensors for the module
*/
int32_t tvmgen_a_run(
struct tvmgen_a_inputs* inputs,
struct tvmgen_a_outputs* outputs
);
7.2.2. Inference Scenarios¶
Multiple models can run on the host processor (ti-npu type=soft) and on the dedicated TI-NPU accelerator (ti-npu) in a variety of combinations.
7.2.2.1. Running all models on Host Processor (ti-npu type=soft)¶
Initialize the input/output data structures for each model. Invoke each model sequentially by calling its inference function.
#include "tvmgen_a.h"
#include "tvmgen_b.h"
tvmgen_a_run(&inputs_a, &outputs_a);
tvmgen_b_run(&inputs_b, &outputs_b);
After tvmgen_a_run returns, model a’s results are available in outputs_a.
After tmvgen_b_run returns, model b’s results are available in outputs_b.
7.2.2.2. Running all models on Hardware NPU Accelerator (ti-npu)¶
Models must run on the Hardware NPU Accelerator sequentially.
After invoking the first model’s inference function, the application needs to check the first model’s volatile variable before invoking the next model’s inference function, because only one model can run on the NPU at a time.
#include "tvmgen_a.h"
#include "tvmgen_b.h"
TI_NPU_init(); /* one time initialization */
tvmgen_a_run(&inputs_a, &outputs_a);
while (!tvmgen_a_finished) ; /* must wait for a to finish before tvmgen_b_run() */
tvmgen_b_run(&inputs_b, &outputs_b);
while (!tvmgen_b_finished) ;
7.2.2.3. Running models on the Host Processor and Hardware NPU Accelerator¶
With two models, you can run one model on the host processor and one model on the Hardware NPU Accelerator. The order in which the model inference functions are invoked could change the total inference time of the two models.
7.2.2.4. Soft, TI-NPU¶
Invoking the host processor (ti-npu type=soft) model before the NPU accelerator (ti-npu) model results in the soft model running to completion before the NPU model begins.
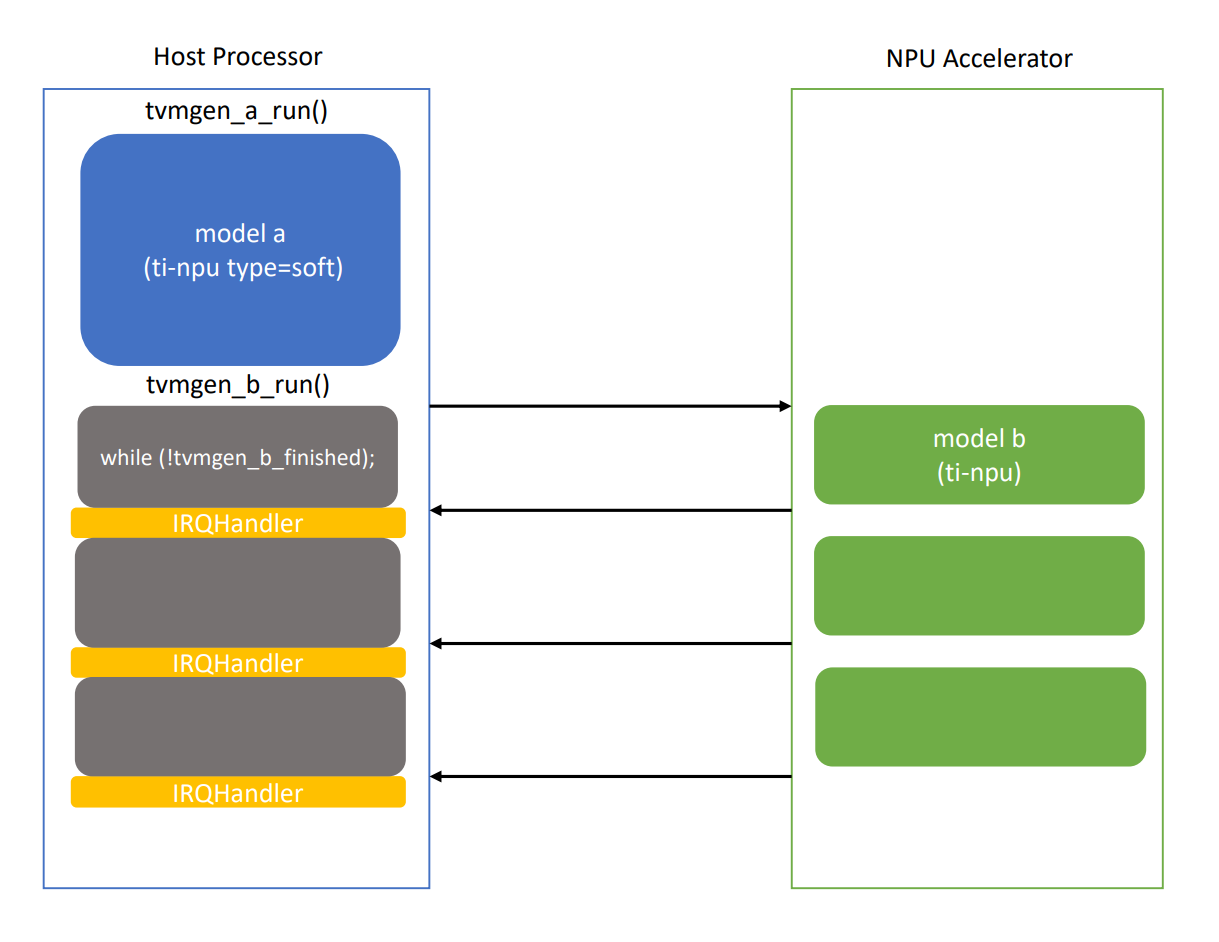
Example code for --module-name=a compiled with (ti-npu type=soft) and --module-name=b
compiled with (ti-npu).
#include "tvmgen_a.h"
#include "tvmgen_b.h"
TI_NPU_init(); /* one time initialization */
tvmgen_a_run(&inputs_a, &outputs_a); /* (ti-npu type=soft) returns on completion */
tvmgen_b_run(&inputs_b, &outputs_b);
while (!tvmgen_b_finished) ;
7.2.2.5. TI-NPU, Soft¶
Invoking the NPU model’s inference function before the soft model’s inference function allows the NPU and soft models to run concurrently. We recommend this approach since it can reduce the total inference time of the two models.
Layers execute on the Hardware NPU Accelerator according to an interrupt-driven sequence. In between accelerator interrupts, the host processor is free to execute the (ti-npu type=soft) model. The illustration below depicts a scenario where the time to execute model “b” on the NPU takes longer than executing model “a” on the host processor. In this scenario, model “a” can run entirely in the free host cycles between interrupts before model “b” completes.
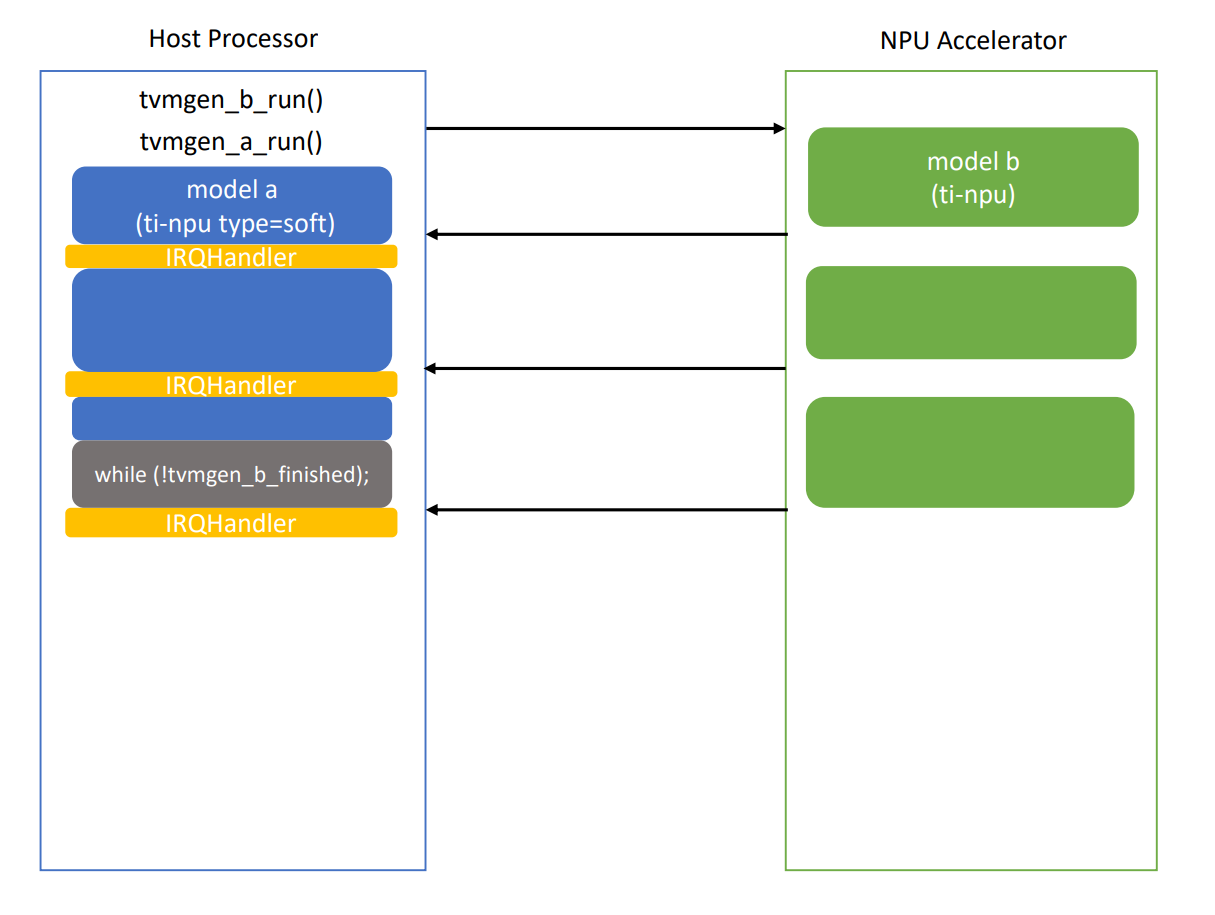
Example code for --module-name=a compiled with (ti-npu type=soft) and --module-name=b compiled
with (ti-npu).
#include "tvmgen_a.h"
#include "tvmgen_b.h"
TI_NPU_init(); /* one time initialization */
tvmgen_b_run(&inputs_b, &outputs_b); /* Interrupt-driven, allows tvmgen_a_run to execute concurrently. */
tvmgen_a_run(&inputs_a, &outputs_a);
while (!tvmgen_b_finished) ;