2. Compilation Explained¶
This section explains how to use the TI Neural Network Compiler for MCUs to compile neural networks.
2.1. Environment Setup¶
For a particular TI family of MCU devices, begin by downloading the corresponding SDK and setting environment variables to help with compilation.
Note
The TI Neural Network Compiler is supported on Windows, Linux and macOS platforms. On Windows, you can use the TI Neural Network Compiler for MCUs in PowerShell or Git BASH. To access Git BASH, download Git for Windows from https://gitforwindows.org/.
Make sure the CGT and SDK installation path below do not contain spaces.
2.1.1. Setup for TI F28x Device Family¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for the TI F28x device family.
Download and install the C28/CLA Code Generation Tools from https://www.ti.com/tool/C2000-CGT.
Define the following environment variables, specifying your CGT installation path, FPU type, and cross compiler options:
Linux / macOS
export C2000_CGT_PATH=/path/to/C2000-CGT export PATH=$C2000_CGT_PATH/bin:$PATH export C2000_DEVICE_FPU=<fpu32, fpu64> # e.g. fpu32 for f28p55x and f2837xd, fpu64 for f28p65x export CL2000_OPTIONS="--float_support=${C2000_DEVICE_FPU} --abi=eabi -O3 --opt_for_speed=5 --c99 -v28 -ml -mt --gen_func_subsections -I${C2000_CGT_PATH}/include -I."
Windows Git BASH
export C2000_CGT_PATH="\path\to\C2000-CGT" export PATH=$C2000_CGT_PATH\\bin:$PATH export C2000_DEVICE_FPU=<fpu32, fpu64> # e.g. fpu32 for f28p55x and f2837xd, fpu64 for f28p65x export CL2000_OPTIONS="--float_support=${C2000_DEVICE_FPU} --abi=eabi -O3 --opt_for_speed=5 --c99 -v28 -ml -mt --gen_func_subsections -I${C2000_CGT_PATH}\\include -I."
Windows PowerShell
$env:C2000_CGT_PATH="\path\to\C2000-CGT" $env:PATH=$env:C2000_CGT_PATH + "\bin;" + $env:PATH $env:C2000_DEVICE_FPU="<fpu32, fpu64>" # e.g. fpu32 for f28p55x and f2837xd, fpu64 for f28p65x $env:CL2000_OPTIONS="--float_support=$env:C2000_DEVICE_FPU --abi=eabi -O3 --opt_for_speed=5 --c99 -v28 -ml -mt --gen_func_subsections -I$env:C2000_CGT_PATH\\include -I."
Note
When setting C2000_CGT_PATH on Windows Git BASH or PowerShell, use Windows-style paths with quotations. For example, "C:\somefolder\".
2.1.2. Setup for TI F29x Device Family¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for the TI F29x device family.
Download and install the C29 Code Generation Tools from https://www.ti.com/tool/C2000-CGT.
Define the following environment variables, specifying your CGT installation path and cross compiler options:
Linux / macOS
export C29_CGT_PATH=/path/to/C29-CGT export PATH=$C29_CGT_PATH/bin:$PATH export C29CLANG_OPTIONS="-O3 -ffast-math -I${C29_CGT_PATH}/include -I."
Windows Git BASH
export C29_CGT_PATH="\path\to\C29-CGT" # e.g. "C:\\ti\\ti-cgt-c29_1.0.0LTS" export PATH=$C29_CGT_PATH\\bin:$PATH export C29CLANG_OPTIONS="-O3 -ffast-math -I${C29_CGT_PATH}\\include -I."
Windows PowerShell
$env:C29_CGT_PATH="\path\to\C29-CGT" # e.g. "C:\\ti\\ti-cgt-c29_1.0.0LTS" $env:PATH=$env:C29_CGT_PATH + "\bin;" + $env:PATH $env:C29CLANG_OPTIONS="-O3 -ffast-math -I$env:C29_CGT_PATH\\include -I."
2.1.3. Setup for TI MSPM0 Device Family¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for the MSPM0 device family.
Download and install the TI ARM Code Generation Tools from https://www.ti.com/tool/ARM-CGT.
Define the following environment variables, specifying your CGT installation path and cross compiler options:
Linux / macOS
export ARM_CGT_PATH=/path/to/ARM-CGT export PATH=$ARM_CGT_PATH/bin:$PATH export TIARMCLANG_OPTIONS_M0="-Os -mcpu=cortex-m0plus -march=thumbv6m -mtune=cortex-m0plus -mthumb -mfloat-abi=soft -I. -Wno-return-type"
Windows Git BASH
export ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" export PATH=$ARM_CGT_PATH\\bin:$PATH export TIARMCLANG_OPTIONS_M0="-Os -mcpu=cortex-m0plus -march=thumbv6m -mtune=cortex-m0plus -mthumb -mfloat-abi=soft -I. -Wno-return-type"
Windows PowerShell
$env:ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" $env:PATH=$env:ARM_CGT_PATH + "\bin;" + $env:PATH $env:TIARMCLANG_OPTIONS_M0="-Os -mcpu=cortex-m0plus -march=thumbv6m -mtune=cortex-m0plus -mthumb -mfloat-abi=soft -I. -Wno-return-type"
2.1.4. Setup for TI Arm Cortex-M33 based devices¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for Arm Cortex-M33 based devices.
Download and install the TI ARM Code Generation Tools from https://www.ti.com/tool/ARM-CGT.
Define the following environment variables, specifying your CGT installation path and cross compiler options:
Linux / macOS
export ARM_CGT_PATH=/path/to/ARM-CGT export PATH=$ARM_CGT_PATH/bin:$PATH export TIARMCLANG_OPTIONS_M33="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m33 -mfloat-abi=hard -mfpu=fpv5-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type" export TIARMCLANG_OPTIONS_M33_CDE="${TIARMCLANG_OPTIONS_M33} -march=thumbv8.1-m.main+cdecp0"
Windows Git BASH
export ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" export PATH=$ARM_CGT_PATH\\bin:$PATH export TIARMCLANG_OPTIONS_M33="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m33 -mfloat-abi=hard -mfpu=fpv5-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type" export TIARMCLANG_OPTIONS_M33_CDE="${TIARMCLANG_OPTIONS_M33} -march=thumbv8.1-m.main+cdecp0"
Windows PowerShell
$env:ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" $env:PATH=$env:ARM_CGT_PATH + "\bin;" + $env:PATH $env:TIARMCLANG_OPTIONS_M33="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m33 -mfloat-abi=hard -mfpu=fpv5-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type" $env:TIARMCLANG_OPTIONS_M33_CDE="${env:TIARMCLANG_OPTIONS_M33} -march=thumbv8.1-m.main+cdecp0"
2.1.5. Setup for TI Arm Cortex-M4 based devices¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for Arm Cortex-M4 based devices.
Download and install the TI ARM Code Generation Tools from https://www.ti.com/tool/ARM-CGT.
Define the following environment variables, specifying your CGT installation path and cross compiler options:
Linux / macOS
export ARM_CGT_PATH=/path/to/ARM-CGT export PATH=$ARM_CGT_PATH/bin:$PATH export TIARMCLANG_OPTIONS_M4="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type"
Windows Git BASH
export ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" export PATH=$ARM_CGT_PATH\\bin:$PATH export TIARMCLANG_OPTIONS_M4="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type"
Windows PowerShell
$env:ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" $env:PATH=$env:ARM_CGT_PATH + "\bin;" + $env:PATH $env:TIARMCLANG_OPTIONS_M4="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -mlittle-endian -O3 -I. -Wno-return-type"
2.1.6. Setup for TI Arm Cortex-R5 based devices¶
Follow these steps to set up your environment for using the TI Neural Network Compiler for MCUs for Arm Cortex-R5 based devices.
Download and install the TI ARM Code Generation Tools from https://www.ti.com/tool/ARM-CGT.
Define the following environment variables, specifying your CGT installation path and cross compiler options:
Linux / macOS
export ARM_CGT_PATH=/path/to/ARM-CGT export PATH=$ARM_CGT_PATH/bin:$PATH export TIARMCLANG_OPTIONS_R5="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-r5 -mfloat-abi=hard -mfpu=vfpv3-d16 -mlittle-endian -O3 -I. -Wno-return-type"
Windows Git BASH
export ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" export PATH=$ARM_CGT_PATH\\bin:$PATH export TIARMCLANG_OPTIONS_R5="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-r5 -mfloat-abi=hard -mfpu=vfpv3-d16 -mlittle-endian -O3 -I. -Wno-return-type"
Windows PowerShell
$env:ARM_CGT_PATH="\path\to\ARM-CGT" # e.g. "C:\\ti\\ti-cgt-armllvm_4.0.3.LTS" $env:PATH=$env:ARM_CGT_PATH + "\bin;" + $env:PATH $env:TIARMCLANG_OPTIONS_R5="-DARM_CPU_INTRINSICS_EXIST -mcpu=cortex-r5 -mfloat-abi=hard -mfpu=vfpv3-d16 -mlittle-endian -O3 -I. -Wno-return-type"
2.2. Compilation Command¶
NNC compiles a neural network (model) into a library that can run on TI MCUs. The following examples demonstrate how the NNC can generate libraries for the TI F28x, F29x, MSPM0, Arm Cortex-M33, Arm Cortex-M4, and Arm Cortex-R5 devices.
2.2.1. TI F28x Device Familly¶
The following example compiles a neural network (model) into a library that can run on an NPU of an F28P55x device.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu" --target-c-mcpu=c28 ./model.onnx -o artifacts_c28/mod.a --cross-compiler="cl2000" --cross-compiler-options="$CL2000_OPTIONS"
Windows PowerShell
tvmc compile --target="c, ti-npu" --target-c-mcpu=c28 .\model.onnx -o artifacts_c28/mod.a --cross-compiler="cl2000" --cross-compiler-options="$env:CL2000_OPTIONS"
In this example:
model.onnxis the input model.artifacts_c28/mod.aspecifiesartifacts_c28as the compilation artifacts directory andmod.aas the generated library.
You can choose different names for the directory and the library.
Note
Compiled model library requires C2000Ware SDK version 26.0 or newer for linking when building an application.
2.2.2. TI F29x Device Family¶
The following example compiles a model into a library that can run on a C29x core of an F29H85x device.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=c29 ./model.onnx -o artifacts_c29/mod.a --cross-compiler="c29clang" --cross-compiler-options="$C29CLANG_OPTIONS"
Windows PowerShell
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=c29 .\model.onnx -o artifacts_c29/mod.a --cross-compiler="c29clang" --cross-compiler-options="$env:C29CLANG_OPTIONS"
2.2.3. TI MSPM0 Device Family¶
The following example compiles a model into a library that can run on an Arm Cortex-M0+ core of an MSPM0 device.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m0plus ./model.onnx -o artifacts_m0/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_M0"
Windows PowerShell
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m0plus .\model.onnx -o artifacts_m0/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_M0"
2.2.4. TI Arm Cortex-M33 based devices¶
The following example compiles a model into a library that can run on an Arm Cortex-M33 core with NPU acceleration.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu" --target-c-mcpu=cortex-m33 ./model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_M33"
Windows PowerShell
tvmc compile --target="c, ti-npu" --target-c-mcpu=cortex-m33 .\model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_M33"
The following example compiles a model into a library that can run on an Arm Cortex-M33 core with CDE acceleration.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=m33cde" --target-c-mcpu=cortex-m33 ./model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_M33_CDE"
Windows Powershell
tvmc compile --target="c, ti-npu type=m33cde" --target-c-mcpu=cortex-m33 .\model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_M33_CDE"
The following example compiles a model into a library that can run an Arm Cortex-M33 core without NPU or CDE acceleration.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m33 ./model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_M33"
Windows Powershell
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m33 .\model.onnx -o artifacts_m33/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_M33"
2.2.5. TI Arm Cortex-M4 based devices¶
The following example compiles a model into a library that can run on an Arm Cortex-M4 core.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m4 ./model.onnx -o artifacts_m4/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_M4"
Windows PowerShell
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-m4 .\model.onnx -o artifacts_m4/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_M4"
2.2.6. TI Arm Cortex-R5 based devices¶
The following example compiles a model into a library that can run on an Arm Cortex-R5 core.
Linux / macOS / Windows Git BASH
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-r5 ./model.onnx -o artifacts_r5/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$TIARMCLANG_OPTIONS_R5"
Windows Powershell
tvmc compile --target="c, ti-npu type=soft" --target-c-mcpu=cortex-r5 .\model.onnx -o artifacts_r5/mod.a --cross-compiler="tiarmclang" --cross-compiler-options="$env:TIARMCLANG_OPTIONS_R5"
2.2.7. Compiler Options¶
You can replace different portions of the example compilation command above using the following options. Note that options following ti-npu can be stacked together. For example, you could change --target="c, ti-npu" to --target="c, ti-npu type=soft skip_normalize=true output_int=true".
Host Processor Options |
Description |
|---|---|
|
Host processor is C28x |
|
Host processor is C29x |
|
Host processor is Arm Cortex-M0+ |
|
Host processor is Arm Cortex-M33 |
|
Host processor is Arm Cortex-M4 |
|
Host processor is Arm Cortex-R5 |
Accelerator Options |
Description |
|---|---|
|
Run layers on an NPU (if exists on the target MCU device). |
|
Run layers with an optimized software implementation on a host processor. |
|
Run layers with CDE acceleration (on supported Arm Cortex-M33 based devices) |
Cross Compiler and Options |
Description |
|---|---|
|
Cross compiler for C28x based MCU devices |
|
Cross compiler for C29x based MCU devices |
|
Cross compiler for TI Arm Cortex-M/R based devices |
|
Use corresponding cross compiler options defined in Environment Setup |
Additional Options |
Description |
|---|---|
|
Skip float to integer input normalization sequence; see Performance Options for details |
|
Skip integer to float output casting; see Performance Options for details |
|
Optimize to save data space; see Performance Options for details |
2.3. Compilation Artifacts¶
Compilation artifacts are stored in the specified artifacts directory—for example, artifacts_c28 and artifacts_c29 in the above compilation command examples.
This artifacts directory will contain:
A header file (for example,
tvmgen_default.h)Generated C code files (for example,
lib0/lib1/lib2.c)A library file (for example,
mod.a)
During compilation, the header file and generated C code files are compiled along with runtime C code files in the tinie-api directory to generate the mod.a library file. This makes the output from the compiler easier to integrate into a CCS project as described in the following section.
2.4. Integrating Compilation Artifacts into a CCS Project¶
2.4.1. Add to CCS Project¶
Follow these steps to integrate the output from the TI Neural Network Compiler for MCUs into a CCS project:
Copy the library and header file from the compilation artifacts directory into the CCS project for the user application.
In the CCS project’s linker command file, place the
.rodata.tvmsection in FLASH, and place the.bss.noinit.tvmsection in SRAM.Ensure that the compiler options used to compile the model are compatible with those in the CCS project properties and the device that will run the application. For example, set the
float_supportoption (C2000_DEVICE_FPU) used to compile the model tofpu32for F28P55x devices and set it tofpu64for F28P65x devices.
2.4.2. Hardware NPU Specific¶
If the hardware NPU accelerator was specified as the target (--target="c, ti-npu") when compiling the neural network, then the CCS project needs the following settings:
Place
.bss.noinit.tvmin global shared SRAM so that hardware NPU can access it. For example,RAMGS0,RAMGS1,RAMGS2, orRAMGS3on an F28P55x MCU device.The hardware NPU requires an interrupt to function. Ensure that the interrupt is enabled in the CCS project. Follow the edgeAI examples in the device SDKs, for example, the empty_npu_ai example in MSPM0 SDK for MSPM0G5187 LaunchPad.
2.5. Performance Options¶
The skip_normalize=true and output_int=true performance options apply only to models that have been quantized for the TI-NPU
or CPU quantized models in QDQ format. See Quantization-Aware Training in PyTorch to quantize an existing PyTorch
model for TI-NPU or CPU-only execution.
2.5.1. Skip Input Feature Normalization (skip_normalize=true)¶
NPU-QAT trained models and CPU quantized QDQ models have an input feature normalization sequence that converts float input data to quantized int8_t/uint8_t data. By default, NNC generates code for this float-to-integer conversion. The NNC can skip input normalization sequences for TI-NPU QAT models or CPU quantized QDQ models.
If the NPU option skip_normalize=true is specified, NNC prunes the model to skip the model’s input feature normalization sequence described below;
instead, it directly computes from integer data.
If this option is specified, the user application should provide integer data—instead of float data—as input to the model.
That is, the user application should perform input feature normalization outside of the NNC-generated code.
Note
There are limitations to the skip_normalize=true optimization, for example, the input feature
normalization sequence needs to be at the beginning of the model, and it does not yet support models with multiple inputs.
If NNC fails to perform this optimization, the generated model library still uses
the data type(s) of the original model input(s).
Refer to the generated header file in the artifacts directory for input data types of the model library.
2.5.1.1. NPU Quantized Models¶
The TI-NPU input normalization sequence is as follows: Add (bias), Multiply (scale), Multiply (shift), floor, and clip to int8_t or uint8_t.

With the skip_normalize=true option specified, the NNC removes this sequence from the model and logs the bias, scale, and shift parameters used for input feature normalization in a generated header file (for example, tvmgen_default.h).
Refer to NPU Quantized Models for an example of performing input normalization in the user application.
2.5.1.2. CPU Quantized Models¶
QDQ models have an initial quantize layer that converts the input data from float to integer using scale and zero point parameters.
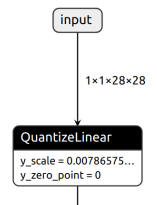
With the skip_normalize=true option specified, the NNC removes the initial quantize layer and logs the scale and zero point for input normalization in a generated header file (for example, tvmgen_default.h).
Refer to CPU Quantized Models for an example of performing input normalization in the user application.
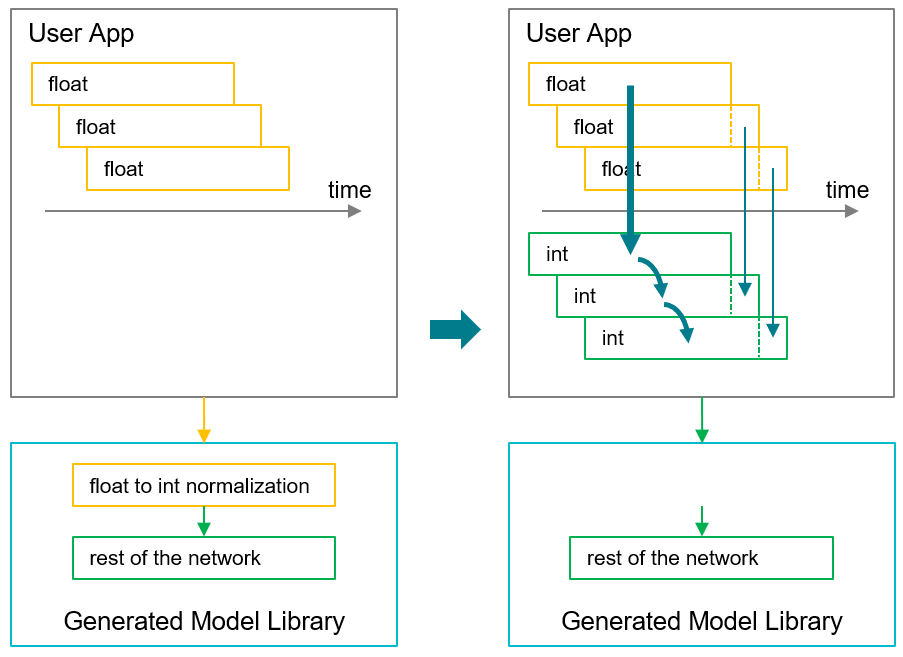
2.5.1.3. Time-Series Data Performance Enhancement¶
The user application may be able to improve performance when processing time-series data in a sliding-window fashion. The application can choose to normalize only new data in the window, while reusing already normalized results for old data in the window.
2.5.2. Skip Output Dequantization (output_int=true)¶
2.5.2.1. NPU Quantized Models¶
NPU-QAT trained models produce float outputs by default. By default, NNC generates code to cast the model output from integer to float, if the original ONNX model output is in float.
When the option output_int=true is specified, NNC prunes the model to skip the final int to float cast and directly outputs the int.
User applications should interpret the inference results as int.
Refer to the generated header file in the artifacts directory for output data types of the model library.
2.5.2.2. CPU Quantized Models¶
QDQ models produce float outputs by default, with a final dequantization layer that converts the output from integer to float with scale and zero point parameters.
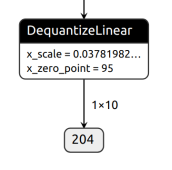
When the option output_int=true is specified, NNC prunes the model to skip the final
dequantization layer and logs the scale and zero point parameters for output dequantization in a generated header file (for example, tvmgen_default.h).
If the user wants the model output in float with the output_int=true option specified, then they should perform the output
dequantization within the user application. Refer to Output Dequantization for CPU Quantized Models for an example.
Note
This output_int=true optimization is not yet supported on QDQ models with multiple outputs.
2.5.3. Optimize for Space (opt_for_space=true)¶
Currently, this option applies only to layers offloaded to the NPU. When opt_for_space=true
is specified, the compiler tries to compress NPU layer data to reduce the read-only data size.
However, such compression can introduce a slight increase in the model’s inference latency.
We recommend that you evaluate this tradeoff before using the option.
2.6. Mapping Between tvmc Command-Line Options and Tiny ML ModelMaker Arguments¶
If you are using TI’s EdgeAI Studio IDE, you will not use the TI Neural Network Compiler for MCUs directly. EdgeAI Studio interfaces with a command-line tool called Tiny ML ModelMaker, which in turn interfaces with the TI Neural Network Compiler.
Tiny ML ModelMaker directly uses parsed arguments instead of the tvmc command line,
For example, the --target-c-mcpu=c28 tvmc command-line option is used as an entry
{"target-c-mcpu" : "c28", ...} in the args dictionary (python) from the Tiny ML ModelMaker tool.