10.8.5. Compression¶
When automatically generating copy tables, the linker provides a way to compress the load-space data. This can reduce the read-only memory foot print. This compressed data can be decompressed while copying the data from load space to run space.
You can specify compression in two ways:
The linker command line option --copy_compression= compression_kind can be used to apply the specified compression to any output section that has a table() operator applied to it.
The table() operator accepts an optional compression parameter. The syntax is:
table(name, compression=compression_kind)
The compression_kind can be one of the following types:
off. Don’t compress the data.
rle. Compress data using Run Length Encoding.
lzss. Compress data using Lempel-Ziv-Storer-Szymanski compression.
A table() operator without the compression keyword uses the compression kind specified using the command line option --copy_compression.
When you choose compression, it is not guaranteed that the linker will compress the load data. The linker compresses load data only when such compression reduces the overall size of the load space. In some cases even if the compression results in smaller load section size the linker does not compress the data if the decompression routine offsets for the savings.
For example, assume RLE compression reduces the size of section1 by 30 bytes. Also assume the RLE decompression routine takes up 40 bytes in load space. By choosing to compress section1 the load space is increased by 10 bytes. Therefore, the linker will not compress section1. On the other hand, if there is another section (say section2) that can benefit by more than 10 bytes from applying the same compression then both sections can be compressed and the overall load space is reduced. In such cases the linker compresses both the sections.
You cannot force the linker to compress the data when doing so does not result in savings.
You cannot compress the decompression routines or any member of a GROUP containing .cinit.
10.8.5.1. Compressed Copy Table Format¶
The copy table format is the same irrespective of the compression_kind. The size field of the copy record is overloaded to support compression. The following figure shows the compressed copy table layout.

Figure 10.5 Compressed Copy Table Layout¶
If the rec_size in the copy record is non-zero it represents the size of the data to be copied, and also means that the size of the load data is the same as the run data. When the size is 0, it means that the load data is compressed.
10.8.5.2. Compressed Section Representation in the Object File¶
The linker creates a separate input section to hold the compressed data. Consider the following table() operation in the linker command file.
SECTIONS
{
.task1: load = ROM, run = RAM, table(_task1_table)
}
The output object file has one output section named .task1 which has different load and run addresses. This is possible because the load space and run space have identical data when the section is not compressed.
Alternatively, consider the following:
SECTIONS
{
.task1: load = ROM, run = RAM, table(_task1_table, compression=rle)
}
If the linker compresses the .task1 section then the load space data and the run space data are different. The linker creates the following two sections:
.task1: This section is uninitialized. This output section represents the run space image of section task1.
.task1.load: This section is initialized. This output section represents the load space image of the section task1. This section usually is considerably smaller in size than .task1 output section.
The linker allocates load space for the .task1.load input section in the memory area that was specified for load placement for the .task1 section. There is only a single load section to represent the load placement of .task1 - .task1.load. If the .task1 data had not been compressed, there would be two allocations for the .task1 input section: one for its load placement and another for its run placement.
10.8.5.3. Compressed Data Layout¶
The compressed load data has the following layout:
8-bit index : compressed data
The first 8 bits of the load data are the handler index. This handler index is used to index into a handler table to get the address of a handler function that knows how to decode the data that follows. The handler table is a list of 32-bit function pointers as shown in the following figure:
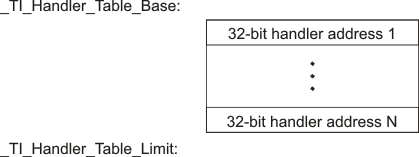
Figure 10.6 Handler Table¶
The linker creates a separate output section for the load and run space. For example, if .task1.load is compressed using RLE, the handler index points to an entry in the handler table that has the address of the run-time-support routine __TI_decompress_rle().
10.8.5.4. Run-Time Decompression¶
During run time you call the run-time-support routine copy_in() to copy the data from load space to run space. The address of the copy table is passed to this routine. First the routine reads the record count. Then it repeats the following steps for each record:
Read load address, run address and size from record.
If size is zero go to step 5.
Call memcpy passing the run address, load address and size.
Go to step 1 if there are more records to read.
Read the first byte from the load address. Call this index.
Read the handler address from (&__TI_Handler_Base)[index].
Call the handler and pass load address + 1 and run address.
Go to step 1 if there are more records to read.
The routines to handle the decompression of load data are provided in the run-time-support library.
10.8.5.5. Compression Algorithms¶
The following subsections provide information about decompression algorithms for the RLE and LZSS formats. To see example decompression algorithms, refer to the following functions in the Run-Time Support library:
RLE: The __TI_decompress_rle() function in the copy_decompress_rle.c file.
LZSS: The __TI_decompress_lzss() function in the copy_decompress_lzss.c file.
Run Length Encoding (RLE):
8-bit index : Initialization data compressed using RLE
The data following the 8-bit index is compressed using run length encoded (RLE) format. Arm uses a simple run length encoding that can be decompressed using the following algorithm. See copy_decompress_rle.c for details.
Read the first byte, Delimiter (D).
Read the next byte (B).
If B != D, copy B to the output buffer and go to step 2.
Read the next byte (L).
If L == 0, then length is either a 16-bit or 24-bit value or we’ve reached the end of the data, read the next byte (L).
If L == 0, length is a 24-bit value or the end of the data is reached, read next byte (L).
If L == 0, the end of the data is reached, go to step 7.
Else L <<= 16, read next two bytes into lower 16 bits of L to complete 24-bit value for L.
Else L <<= 8, read next byte into lower 8 bits of L to complete 16-bit value for L.
Else if L > 0 and L < 4, copy D to the output buffer L times. Go to step 2.
Else, length is 8-bit value (L).
Read the next byte (C); C is the repeat character.
Write C to the output buffer L times; go to step 2.
End of processing.
The Arm run-time support library has a routine __TI_decompress_rle24() to decompress data compressed using RLE. The first argument to this function is the address pointing to the byte after the 8-bit index. The second argument is the run address from the C auto initialization record.
Note
RLE Decompression Routine The previous decompression routine, __TI_decompress_rle(), is included in the run-time-support library for decompressing RLE encodings that are generated by older versions of the linker.
Lempel-Ziv-Storer-Szymanski Compression (LZSS):
8-bit index |
Data compressed using LZSS |
The data following the 8-bit index is compressed using LZSS compression. The Arm run-time-support library has the routine __TI_decompress_lzss() to decompress the data compressed using LZSS. The first argument to this function is the address pointing to the byte after the 8-bit Index, and the second argument is the run address from the C auto initialization record.
See copy_decompress_lzss.c for details on the LZSS algorithm.