|
TIOVX User Guide
|
|
TIOVX User Guide
|
For general pipelining usage guidelines, please follow the Khronos OpenVX pipelining extension here
Pipelining in OpenVX requires an understanding of graph parameters and node parameters. The below sections link to the explanation of these concepts in the OpenVX spec.
Graph Parameters : Graph parameters are used in the non-streaming, pipelining mode to identify the parameters within a graph that are user-enqueueable. By creating a graph parameter and explicitly enqueue-ing and dequeue-ing this parameter from the graph, the application has the ability to access the object data. Otherwise, when using pipelining, non-graph parameters are not accessible during graph execution.
Node Parameters : In the TIOVX implementation, node parameters are used to identify where multiple buffers need to be created in the case of pipelining. This is explained further in the Buffer depth section. If buffer access from the application is needed, the parameter in question should be created as a graph parameter given that multiple buffers will be created at that parameter and there is not a way of accessing a particular buffer of this buffer queue.
The following section details how to get the best performance and how to optimize the memory footprint of an OpenVX graph. In order to do so, the concepts of graph pipeline depth and buffer depth must be understood in the context of the TIOVX framework. The following two sections provide details about these concepts.
As of Processor SDK 7.2, the TIOVX framework has been enhanced to enable automatic graph pipelining depth and buffer depth setting. This alleviates the burden of the application developer to set these values in order to get real time performance. While the framework will set these values automatically, they can be overwritten by the respective API's used for setting these values. Further explanation is provided in the sections below.
In order to for an OpenVX graph to get full utilization of TI's heterogeneous SoC's, the OpenVX graph must be pipelined. In the TIOVX framework, the characteristic which describes the utilization of the heterogeneous cores is the pipeline depth. Consider a simple 3 node graph seen in the image below. This graph uses 3 cores on the SoC: an ISP, DSP and CPU.
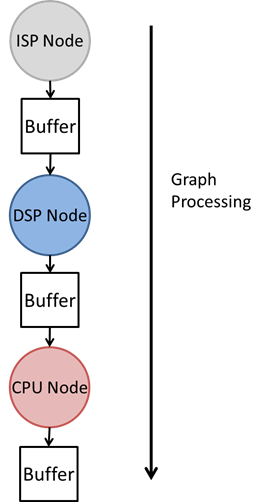
Without pipelining, a new graph execution would not be able to begin until the initial graph execution was completed. However, since each of these cores can be running concurrently, this graph execution does not allow for the best hardware utilization. The TIOVX pipelining implementation allows for full hardware utilization by internally creating multiple instances of the graph based on the value of the pipeline depth. Therefore, each of these graphs will execute simultaneously, such that each core is actively processing. In this scenario, the optimal pipeline depth is 3. With a pipeline depth of 3, the framework treats the graph as if there were 3 instances of the same graph processing simultaneously as shown below. The image below shows the graph processing at time T=2, such that every processing unit was active.
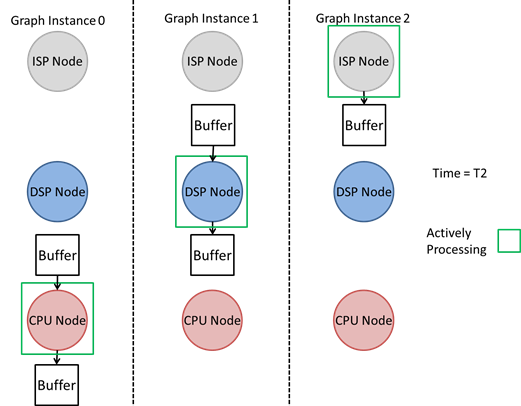
By parsing the structure of the graph, the TIOVX framework can automatically set the pipeline depth and achieve real time performance. The automated pipe depth feature sets the pipe depth during the vxVerifyGraph call based on the structure of the graph. For instance, in the example above, the framework will set the pipeline depth to 3, thereby allowing each node in the graph to execute.
The value used as the pipe depth is determined by doing a depth search to find the longest sequence of consecutive nodes within a graph. This methodology is intended to return a pipeline depth that provides the best performance by considering the worst case scenario of OpenVX node target assignment. (For more information about TIOVX targets, see Explanation of Targets in TIOVX.) For instance, if in the example above, the OpenVX nodes were all assigned to run on the CPU, the TIOVX framework would still set a pipeline depth of 3.
If the calculated pipe depth value exceeds the TIVX_GRAPH_MAX_PIPELINE_DEPTH, the value will be set to the max allowable depth and a warning will be thrown. This value can be increased if necessary by modifying the TIVX_GRAPH_MAX_PIPELINE_DEPTH macro in the file tiovx/include/TI/tivx_config.h.
In order to further fine tune and potentially optimize the OpenVX graph, the application developer has the option to set the pipeline depth directly via the tivxSetGraphPipelineDepth API. In this case, the framework will use the value provided by the application rather than the calculated value. However, if this value is less than the optimal value as calculated by the framework, a message will be printed to the console using the VX_ZONE_OPTIMIZATION logging level indicating to the user that this value may not be optimal. By using the tivxSetGraphPipelineDepth API, the application developer can potentially reduce the memory footprint of the graph in the case that real time performance can be achieved by using a smaller pipeline depth value than detected by the framework. In order to know the value the framework is using for pipeline depth, the user can call the vxQueryGraph API using the TIVX_GRAPH_PIPELINE_DEPTH macro after calling vxVerifyGraph.
It is not recommended to use vx_delay objects when using pipelining with TIOVX. The delay objects will unintentionally create serializations in the graph and break the desired pipelining.
Instead of using delay objects, graph parameters can be used to emulate a delay in the graph, thus allowing the delay to be handled in the application.
In order for a node producing a buffer to operate concurrently with a node consuming that buffer, multiple buffers must be used at the buffer parameter in order to avoid pipelining stalls. This is illustrated in the diagram below.
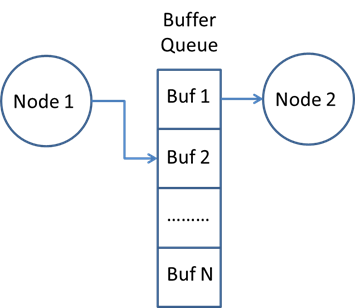
As defined in the pipelining specification of OpenVX, a buffer can be created as a graph parameter with multiple buffers created within the application. (For more information on this, see Node and Graph Parameter Definitions.) In the case that graph parameters are not used, there is not a native OpenVX API to set multiple buffers at a given node parameter.
In order to allow the OpenVX graph to run with full performance without changing the native implementation of OpenVX, the TIOVX framework will automatically allocate and set the multiple buffers during the vxVerifyGraph call according to the node connections of the buffer. The value used as the buffer depth of a particular parameter is found by detecting the total number of nodes connected to a given buffer. For instance, let us consider the example from the previous section. Since each buffer is connected to a single producer node and a single consumer node, the framework will set the buffer depth of each of these parameters to 2 as shown in the below diagram.
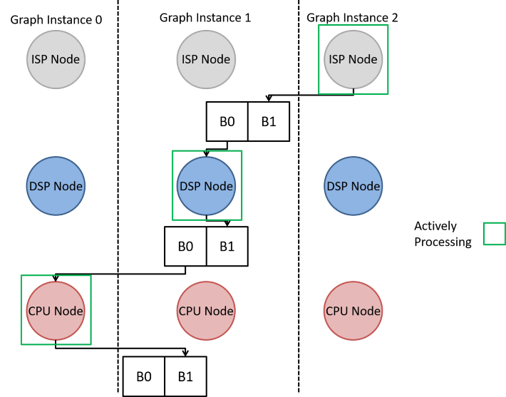
This feature excludes parameters that have already been enabled as graph parameters given that these parameters require the buffer to manually be enqueued and dequeued from the application, therefore requiring the buffer depth to be set in the application.
In order to further fine tune and potentially optimize the OpenVX graph, the application developer has the option to set the buffer depth directly via the tivxSetNodeParameterNumBufByIndex API. (The parameter being set to use multiple buffers using this API must not already be created as a graph parameter. Otherwise, an error will be thrown during vxVerifyGraph.) If the tivxSetNodeParameterNumBufByIndex API is used, the framework will use the value provided by the application rather than the calculated value. However, if this value is less than the optimal value as calculated by the framework, a message will be printed to the console using the VX_ZONE_OPTIMIZATION logging level indicating to the user that this value may not be optimal. By using the tivxSetNodeParameterNumBufByIndex API, the application developer can potentially reduce the memory footprint of the graph in the case that real time performance can be achieved by using a smaller buffer depth value than detected by the framework. In order to know the value the framework is using for pipeline depth, the user can call the tivxGetNodeParameterNumBufByIndex after calling vxVerifyGraph.
Composite objects are a special consideration when pipelining using TIOVX. In this context, the definition of a composite object is an OpenVX object that serves as a container for other OpenVX objects. A list of composite objects are given below along with a graph construction suggestion. An explanation for these situations is given in the section below.
Object Arrays and Pyramids are treated similarly in TIOVX from a pipelining perspective. There are many common pipelining scenarios using these objects which arise when developing an application using TIOVX. The following examples illustrate how a graph with object arrays MUST be constructed using TIOVX. Even though the example uses object arrays, the same principles can be applied to the pyramid object with no difference in implementation.
Object arrays are used prevalently in multi-sensor TIOVX applications, such as with the tivxCaptureNode() which outputs an object array and has as its elements the individual sensor images. These elements will often be processed by downstream nodes, such as the tivxVpacVissNode() that takes as an input an individual element of the object array, rather than the full object array. This interaction can be seen in the block diagram below.
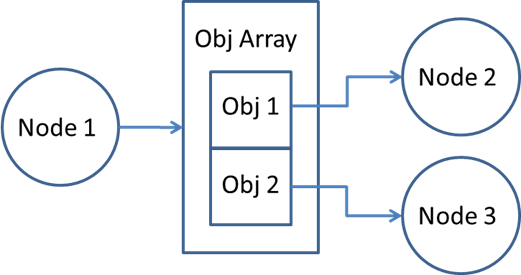
Similarly, the output objects of multiple nodes may consist of elements of object arrays which then are consumed by a single node in the form of the full object array. As an example, this situation occurs when creating a Surround View application with TIOVX. The individual output images from multiple instances of the VISS node form a single object array, which is consumed by a node generating the Surround View output. This interaction can be seen in the diagram below.
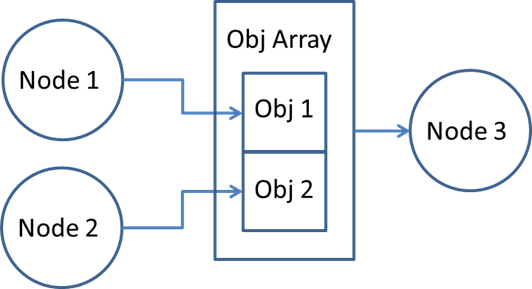
OpenVX natively supports two options for supporting the above interaction of sending separate elements of an object array to downstream nodes for processing. The first option is to use the vxReplicateNode() feature. By using this feature, the application developer avoids re-writing large portions of code by allowing the framework to instantiate as many instances of the node as there are elements in the object array while retaining the ability to customize specific parameters of the node.
The second option OpenVX provides for accessing elements of object arrays is to use the vxGetObjectArrayItem() API. This option is NOT natively supported with pipelining in TIOVX. Therefore, the recommendation is to use the replicate node feature. However, if the replicate node feature cannot be used within the application, a workaround is available when the object array is the output of the producing node and the object array elements are the input of the consumer node. This workaround requires a slight modification of the kernel that is consuming the object array.
Within the OpenVX graph, the vxGetObjectArrayItem() API is called to extract the 0th element of the object array output of the producer node. This element is then passed to the input of the consumer node. In order to extract the appropriate object array item within the kernel consuming the element, the tivxGetObjDescElement() API can be called with the arguments being the object descriptor of the object array element and the appropriate element ID of the object array. This API will then return the object descriptor of the element given as the elem_idx argument. This elem_idx can be provided via a config parameter or sent via the tivxNodeSendCommand() API depending on the requirements of the kernel. Internally, this API has logic to determine whether or not the input object descriptor is in fact an object array element. If it is not an object array element, it will return the original object descriptor. This provides flexibility to the kernel to handle both the case of if input element is an object array element or non-object array element. An example of this workaround can be found within the display node (video_io/kernels/video_io/display/vx_display_target.c). Note: due to the limitation of the framework, the kernel itself will choose the object array element rather than the application. Therefore, the element ID passed to the vxGetObjectArrayItem() API within the application is ultimately ignored and must be programmed within the kernel.
ROI Images are supported in the non-pipelined implementation of TIOVX. However, pipelining a graph containing ROI images is not supported in TIOVX.
Note: If support for ROI images is required for your application, please request support from your local TI sales representative.
When using graph parameters with the vxReplicateNode feature of OpenVX, there are a few unique scenarios as described above to appropriately pipeline the graph.
Scenario 1: As defined in the OpenVX specification, a node that is replicated uses an element of a composite object (either an object array or a pyramid) with a depth of that object equal to the number of total replicated nodes. Consider the following scenario when using vxReplicateNode() for pipelining. The node has input and output images that are elements of an object array. In the case that the application needs to access this image data inside application, this parameter must be created as a graph parameter. In this case, the first element of the object array is required to be created as the graph parameter, rather than the entire object array itself.
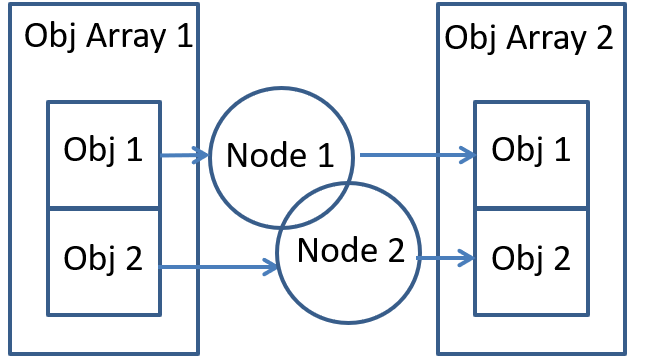
Scenario 2: Let us now consider another similar scenario. In the situation below, the object array which is used as an input to the replicated node is also being provided as an input to another node. Whereas the replicated node takes as an input parameter an element of the array, the other node takes as a parameter then entire object array itself. In this scenario it is required to create the graph parameter from the entire object array rather than just the element of the object array as in Scenario 1.
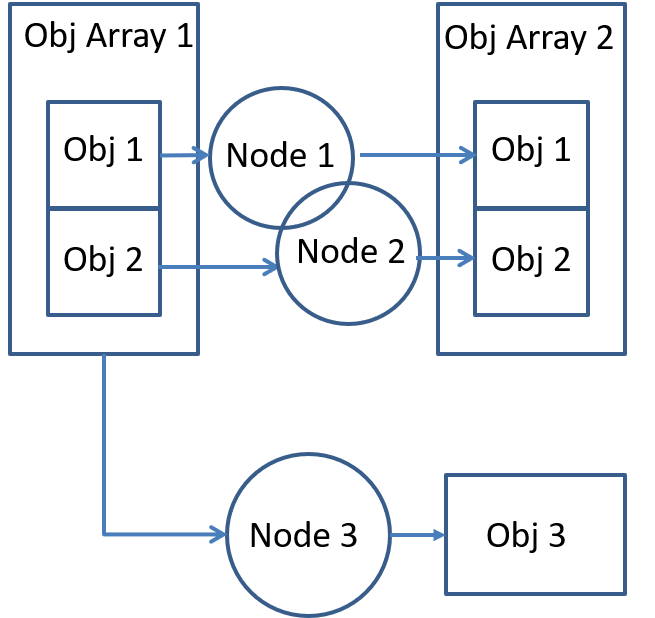
When setting up data references to send as a parameter of the vxSetGraphScheduleConfig API, all the data references in the list must contain the same meta data as all others in the list of data references. There is presently no validation of the full list of data references done by the framework. The vxVerifyGraph performs checks based on the validate callback of each kernel, but this will only validate the first data reference of the list. In the case that subsequent data references have different meta-data than the first, the framework will not validate this. Therefore, all data references must consist of the same meta-data. A validation check has been added to the vxSetGraphScheduleConfig API to flag this scenario.
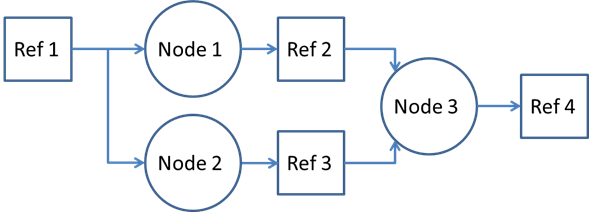
Consider the graph below. In the case that Ref 1 is to be made a graph parameter, only a single graph parameter should be made of this reference and it can be made from either node parameter. Therefore, the reference will be dequeued once both the nodes that are consuming the reference are completed. Note, this is only required when the given parameter is at the edge of the graph (i.e., the parameter is not an output of a preceding node.) In the case that it is an internal buffer to a graph and needs to be made as a graph parameter, the graph parameter is created from the output node parameter.
 1.8.14
1.8.14