Deep Neural Network (DNN) based machine learning algorithms are used in many industries such as robotics, industrial and automotive. These algorithms are defined in the form of deep networks with millions of learnable parameters. TIDL-RT is designed and developed to accelerate these algorithms on TI devices (using purpose-built processors). It abstracts all hardware complexities and allows users to focus on defining these algorithms without worrying about optimal deployment.
TIDL-RT is designed with the following fundamental properties:
- Interoperability: There are many tools/frameworks (e.g. TensorFlow, Pytorch etc.) available in the machine learning community for DNN design and training. After training, these frameworks provide the network in a specific format (referred to as an exchange format) which is not universal and differs from one framework to another. Most of these frameworks provide the network parameters in floating-point format whereas few of them like TFLite can also provide in fixed-point integer format. TIDL-RT is interoperable with most of these exchange formats and can accept both floating-point and fixed-point formats.
- Best Accuracy: TIDL-RT is aimed to provide best-in-class accuracy with state-of-the-art Post Training Quantization (PTQ) and calibration algorithms. C7x-MMA can accelerate operations using 8-bit and 16-bit data bit-depth significantly better compared to floating-point. Operating in 8-bit and 16-bit requires quantization of floating-point networks to a fixed-point format. TIDL-RT provides PTQ and advanced calibration methods to minimize the accuracy loss for fixed point inference. TIDL-RT also provides mixed-precision inference allowing some portions of the network to be inferred with 8-bit fixed-point precision and other portions with 16-bit fixed-point precision. TIDL-RT does not support floating-point format based inference on development boards.
- Best Performance: TIDL-RT is aimed to provide the best execution time for latency sensitive deployment of DNNs. These DNNs have millions of parameters and complex graph structures with multiple layers requiring Giga to Tera MACs of compute capability and very high (10s of Giga bytes/sec) memory bandwidth. TIDL-RT makes efficient use of available TOPs on C7x-MMA and on-chip memories available on TI devices resulting in a highly optimal solution both in terms of execution time and memory bandwidth. TIDL-RT is not only designed to accelerate small (eg 224x224) image resolutions but it also optimally infers higher resolutions such as 2-4 MP image inputs. TIDL-RT also provides batch support to further improve the performance.
- Scalability: Scalability is very critical in DNN space and the solution has to be scalable in many dimensions:
- Network Structure: There are many network topologies built with a variety of building blocks such as bottleneck, fire, inception, residual connections and many more. TIDL-RT is designed to be flexible enough to handle all styles of current as well as future network structures.
- Resolution: Design choices of the inference solution can vary depending on resolution of the incoming data w.r.t to placement of feature maps and feature coefficients on different on-chip memories. TIDL-RT is designed to work optimally with different resolutions.
- Hardware Capability: TI provides a portfolio of scalable embedded devices with varying on-chip memory size, external memory bandwidth and compute capabilities (from less than 1 TOPS to 10s of TOPs). TIDL-RT is designed to be scalable across devices with different hardware capabilities.
- Sensor Modalities: DNNs are suitable for different sensor modalities like vision, radar, lidar and many more. TIDL-RT is designed to be scalable across many sensor modalities.
TIDL-RT also has the flexibility to add custom operators (by end users) if operators needed are not supported by TIDL-RT.
The figure below provides an overview of key software modules of TIDL-RT:
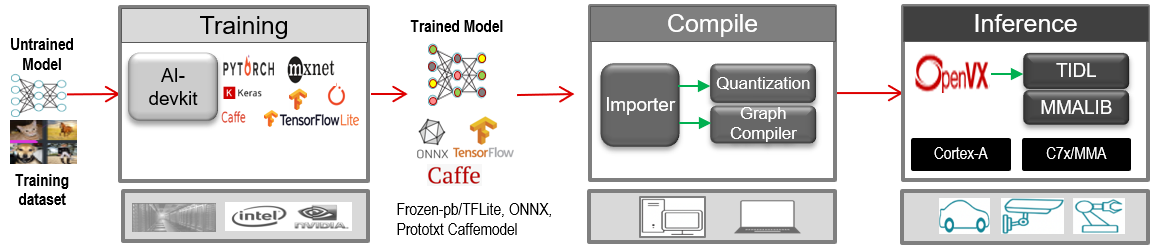
Fundamental blocks of TI Deep Learning Product
TIDL-RT provides 2-stage deployment of a DNN after it is trained:
- Compile : This stage is performed on a X86 computer and an executable tidl_model_import.out is provided to perform this stage. During this stage, the DNN gets imported to TI's internal exchange format. The compilation stage also performs quantization of the DNN and in order to do this, it requires representative calibration images. After quantization, this executable internally calls TI's DNN graph compiler and prepares the execution plan of the DNN on the target SOC. To keep it scalable across different SOCs, the executable accepts the device properties via a device configuration file. More details of this can be found in TIDL Importer.
- Inference : After compilation, several artifacts are generated and using these artifacts a DNN can be inferred on TI SOCs optimally. In order to do this, one needs a development board having TI device for which the DNN is compiled. TI provides development boards which can be ordered from TI or its partner website. For example, the TDA4VM development board can be ordered here. TIDL-RT also provides a PC based inference mechanism which can be performed on a X86 PC without any development board to understand the functional behavior of TIDL-RT. Performance measurement can only be done on a development board. More details of inference can be found in the TIDL Inference section. Please refer to the build Instructions for more details on how to build for PC inference.
 1.8.13
1.8.13