Introduction
- The floating point computations are not cost and power efficient. These floating point computations can be substituted with fixed point computations (8 or 16 bit) without losing inference accuracy.
- Matrix Multiplier Accelerator (MMA) in ADAS/AD SOC of Jacinto7 family supports 8-bit, 16-bit and 32-bit inference of Deep Learning models.
- 8-bit inference supports a multiplier throughput at 4096 MACs per cycle when doing 64x64 matrix multiply. Hence 8-bit inference is desired to be used for these SOC
- 16-bit and 32-bit will come with significant performance penalty
- 16-bit inference multiplier throughput is 1024 MACs per cycle
- Memory I/O needed would be high
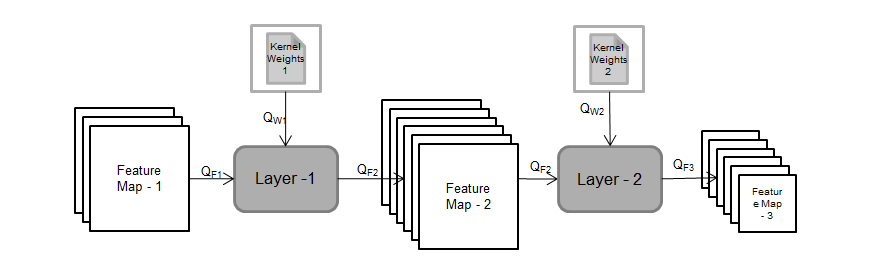
In TIDL, the scales for each Parameter, and feature Maps are selected separately based their range (Minimum and Maximum values). The scales are passed through layer processing from producer layer to consumer layer till last layer. All the feature maps and parameters are maintained in fixed point representation and associated floating point scale. At the end user can convert the final output tensors to floating point by dividing each element in the tensor by corresponding floating point scale.
TIDL - Basic Quantization
The are multiple schemes to select the scale for a given tensor based on the expected range. The scale values could be power of two for optimal implementation based on supported device architecture. The image below show two schemes for selecting scale for signed tensor

TIDL - Scale Selection Schemes
If the tensor data is unsigned (for example output of ReLU layer), then the entire range can be used for representing positive range only. This would help in achieving lesser quantization error.

TIDL - Scale Selection Schemes
TIDL SW supports:
- Both Power of two scales (TIDL_QuantStyleP2Dynamic) and Non-power two scales (TIDL_QuantStyleNP2Fixed) for Parameters/Weights. User can configure one of them.
- Power of two scales for Feature maps.
TIDL Layers which Requires Parameter Quantization
- Convolution Layer
- De-convolution Layer
- Inner-Product Layer
- Batch Normalization (Scale/Mul, Bias/Add, PReLU)
Quantization Options
TIDL provides below quantization options to the user
- A. Post Training Quantization (PTQ)
- B. Guidelines For Training To Get Best Accuracy With Quantization
- C. Quantization Aware Training (QAT)
We recommend to use option 'A' for network first, if the quantization accuracy loss is not acceptable, then you can try option 'B'. The result with 'B' also not acceptable, then user can use option 'C'. This solution shall work all the time. The only drawback of this solution is that, this would need addition effort from user to re-train the network.

TIDL - Quantization Options
A. Post Training Quantization (PTQ)
- Training free Quantization – Most preferred option by user.
- This option also has further options available.
- Simple Calibration
- Advanced Calibration
- Per Channel weight quantization for depthwise convolution Layers
- Mixed Precision
- Future/Planned Improvements
A.1. Simple Calibration
- This option is the default option of TIDL.
- Supports Power of 2 or Non Power of 2 scale's for parameters
- Supports only power of 2 scales for feature maps
- Scale selected based on min and max values in the given layer.
- Range for each feature maps are calibrated offline with few sample inputs.
- Calibrated range (Min and Mix) Values are used for Quantizing feature maps in target during inference (real time).
- Option to update range dynamically – Has performance Impact
- Observed accuracy drop less than 1% w.r.t floating point for many networks with 8-bits.
- Models such as Resnets, SqueezeNet, VGG etc ( specially models which don't use Depthwise convolution layers).
A.2. Advanced Calibration
- This feature should be used if 8 bit accuracy is not in acceptable range with simple calibration as described above. There are multiple options which are available to user for this and user can incrementally try these options to see if accuracy is in acceptable range. Following are the various options available:
A.2.1. Histogram based activation range collection:
- To enable this feature user needs to only set calibrationOption to 1 in import config file. Typically no other parameter is required to be set as default parameters works for most of the cases.
- This feature uses histogram of feature map activation range's to remove outliers which can affect the overall range. This helps in reducing the loss due to quantization.
- User can also experiment with following parameters related to this option if required:
- percentileActRangeShrink: This parameter is percentile of the total number of elements in a activation tensor which needs to be discarded from both side of activation distribution. If input is unsigned then this is applied to only one side of activation distribution. For example percentileRangeShrink = 0.01, means to discard 1/10000 elements from both or one side of activation distribution.
A.2.2. Advanced Bias calibration:
- To enable this feature user needs to only set calibrationOption to 7 in import config file. Typically no other parameter is required to be set as default parameters works for most of the cases. Typically it is observed that using 10 images gives considerable accuracy boost.
- This feature applies a clipping to the weights and update the bias to compensate the DC errors occurring. To understand details of this feature please refer the following Link
- User can also experiment with following parameters related to this option if required:
- biasCalibrationFactor: Each iteration the difference between the per channel floating point mean and quantized mean output of activation range is used to update the bias. This parameter is used to indicate the contribution of this difference which should be used to update the bias. User can always use the default value
- biasCalibrationIterations: Number of iteration to be used for bias calibration.
- numFramesBiasCalibration: Number of input frames to be used for bias calibration
A.3. Per Channel weight quantization for depthwise convolution Layers :
- To enable this feature user needs to set calibrationOption to 13 in import config file. Typically no other parameter is required to be set as default parameters works for most of the cases.
- This feature enables per channel quantization for weights for depthwise separable convoltion layers in the network. Currently this feature is only supported with power of 2 quantization i.e. quantizationStyle = 3. Even if user sets it to anything else internally this will be converted to power of 2.
A.4. Mixed Precision :
- This feature allows user to run only certain layers in higer precision ( i.e. in 16 bit) whereas rest of the network runs in 8 bit. As the precision keeps changing throughout the network this feature is called as Mixed Precision.
- User can use this feature using following ways :
- By setting calibrationOption for some pre-defined configurations. Following are the details of these configuration options :
- Mixed precision for all depthwise convolution layers ( calibrationOption = 16) : When this option is enabled all the depthwise convolution layers weights will be quantized to 16 bits.
- First layer processing in 16 bit ( calibrationOption = 32) : When this option is enabled the first layer's weight of the network will be quantized to 16 bits.
- If user is already using some calibrationOption then they can do a bit wise "OR" with the above two options and provide during import.
- User can get the final output of the network ( given its convolution layer ) in 16 bit by setting corresponding outElementSize for the 1particular output to 2 bytes from the import config.
- Manually selecting layers for mixed precision :
- User can manually specify the layers which they want to run in higher precision ( i.e. in 16 bits) using outputFeature16bitNamesList and params16bitNamesList parameters of import configuration. Please refer here to understand the details of these parameters. User has option to either increase only parameters/weights precision to 16 bit or to have both activation and parameters of a particular layer in 16 bit.
- TIDL allows change of precision for certain set of layers ( mentioned below ) and rest all others can not change precision. This means the layers which support change in precision can have input, output and parameters in different precision. Whereas the layers which do not support change in precision will always have input, output and parameters in same precision. The impact of this is that for a particular layer which doesn't support change in precision, the input, output and parameters precision will be automatically determined based on the producer or consumer of the layer. For example if concat layers which doesn't support change precision, if the output is in 16 bit because of its consumer layer or user requested for the same then it will change all its input also to be in 16 bits.
- If for a given layer output is already a floating point output (e.g. Softmax, DetectionOutputLayer etc) then increasing activation precision has no impact.
- Few Points to Note:
- Currently following layers support change in precision and for all the other layers cannot have input and output in different precision i.e. their precision is determined by their producer/consumer and both input and output will be in the same precision :
- TIDL_ConvolutionLayer ( Except TIDL_BatchToSpaceLayer and TIDL_SpaceToBatchLayer)
- TIDL_BatchNormLayer
- TIDL_PoolingLayer ( Excluding Max pooling layer)
- TIDL_EltWiseLayer
- In future release we will have option to enable automatic selection of each layer's precision.
A.5 Future/Planned Improvements
- Below options are not supported in current release but are planned for future TIDL release.
- Mixed Precision – Automatic selection of layers for mixed precision
- Per Channel Weight Quantization with non-power of 2 quantizationStyle
B. Guidelines For Training To Get Best Accuracy With Quantization
- For best accuracy with post training quantization, we recommend that the training uses sufficient amount of regularization / weight decay. Regularization / weight decay ensures that the weights, biases and other parameters (if any) are small and compact - this is good for quantization. These features are supported in most of the popular training framework.
- We have noticed that some training code bases do not use weight decay for biases. Some other code bases do not use weight decay for the parameters in Depthwise convolution layers. All these are bad strategies for quantization. These poor choices done (probably to get a 0.1% accuracy lift with floating point) will result in a huge degradation in fixed point - sometimes several percentage points. The weight decay factor should not be too small. We have used a weight decay factor of 1e-4 for training several networks and we highly recommend a similar value. Please do no use small values such as 1e-5.
- We also highly recommend to use Batch Normalization immediately after every Convolution layer. This helps the feature map to be properly regularized/normalized. If this is not done, there can be accuracy degradation with quantization. This especially true for Depthwise Convolution layers. However applying Batch Normalization to the very last Convolution layer (for example, the prediction layer in segmentation/object detection network) may hurt accuracy and can be avoided.
- To summarize, if you are getting poor accuracy with quntization, please check the following:
- (a) Weight decay is applied to all layers / parameters and that weight decay factor is good.
- (b) Ensure that all the Depthwise Convolution layers in the network have Batch Normalization layers after that - there is strictly no exception for this rule. Other Convolution layers in the network should also have Batch Normalization layers after that - however the very last Convolution layer in the network need not have it (for example the prediction layer in a segmentation network or detection network).
C. Quantization Aware Training (QAT)
- Model parameter are trained to comprehend the 8-bit fixed point inference loss.
- This would need support/change in training framework
- Once a model is trained with QAT, the future map range values are inserted as part of the model. There is no need to use advanced calibration features for a QAT model. Example – CLIP, Minimum, PACT, RelU6 operators.
- Accuracy drop could be limited to very close to zero.
- Jacinto AI DevKit provides tools and examples to do Quantization Aware Training. With the tools provided, you can incorporate Quantization Aware Training in your code base with just a few lines of code change. For detailed documentation and code, please visit: Link
Handling of ReLU6
- Rectified linear unit (ReLU) is used as activation in layers of many CNN (for vision processing) networks.
- Unlike sigmoid activation (which is used in Traditionally neural networks) the ReLU layers activations values range can be very large based on the input.
- To make the feature activation range restricted, the recent networks uses ReLU6 as activation instead of RelU. Example : MobileNet v1 and MobileNet V2 trained in tensorflow.
- Implementing saturation to 6 in fixed point inference would need floating point computation / Look up table. Floating point computation / Look up table are not efficient in terms of cost and power.
- To overcome this we Propose following :
- Fine tuning the network by replacing ReLU 6 with RelU.
- Train the network with power of two threshold (ReLU 4 or ReLU 8). This can be achieved by using Minimum or CLIP operators
- If fine tuning is not desired solution, we propose replacing ReLU6 with ReLU8 in inference (instead of ReLU). This is automatically done by TIDL
- ReLU8 can be performed with just shift operation in fixed point inference without needing a floating point computation /look up table.

TIDL - Relu6
The table above compares the accuracies of two networks (viz. MobileNetV1 and MobileNetV2) when using different kinds of ReLU activations: ReLU vs ReLU6 vs ReLU8.
 1.8.14
1.8.14