|
Speech Recognizer Project Users Guide
v1.00.00.00
|
|
Speech Recognizer Project Users Guide
v1.00.00.00
|
The MinHMM Library implements a fixed-point speaker-dependent speech recognizer targeted toward embedded processors. The library provides easy-to-use APIs that can voice enable applications. Resources in addition to the library include an example project illustrating the use of MinHMM.
Prior to using a speaker-dependent speech recognizer, the user must train the recognizer with each phrase to recognize by speaking the phrase several times. During training, the recognizer creates a model of each phrase to use during the recognition process. The performance of the recognizer is thus tied to the speaker that trained each phrase. If another speaker tries to use the recognizer, performance will likely degrade due to differences in the way the phrase is spoken.
The MinHMM Library software provides a comprehensive set of APIs for speaker-dependent speech recognition for a wide variety of embedded applications. MinHMM APIs allow an application to perform the following operations.
Obtain information about a model
MinHMM provides the size, name, amount of training, and whether a model is enabled, along with a count of the total number of models.
Run recognition search
The application can utilize MinHMM APIs to run the search continuously, or the search can be suspended after a phrase is recognized. The latter method can be used to implement a "push-to-talk" mode of operation.
MinHMM contains features to balance performance with available processing resources.
Audio activity detection
This limits processing when only background noise is present.
Background compensation
MinHMM dynamically adjusts for slowly changing background noise levels.
Adjustable parameters to tune recognition performance
Default parameter settings are acceptable for most situations. However, MinHMM provides parameters that can be set to tune for recognition performance based on available processing capabilities.
Using MinHMM in an application typically involves four main steps, initializing the MinHMM instance, creating phrase models (also known as enrolling models), training existing phrase models by updating the model parameters with additional data, and performing recognition.
The application starts using MinHMM by initializing the recognizer. Initialization sets up the recognizer instance for use. It requires the user to provide the location, size, and type of memory where model data is stored. Model memory will usually be non-volatile, such as flash or FRAM. If models will use flash memory, the starting location must be on a flash sector boundary and the size must be a multiple of the sector size.
Initialization also requires the user to provide the location and size of RAM that MinHMM can use for processing. This memory is divided into a small amount of memory that must persist during the use of MinHMM, and a larger amount of processing memory used only during model creation, update, and recognition. The application can reuse the processing memory when MinHMM is not performing one of these operations.
The example project includes code that illustrates and assists in setting up the model and RAM memory properly.
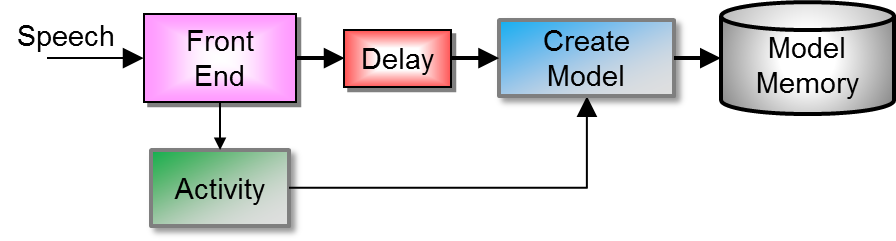
The application must create models of the phrases to be recognized. A block diagram of the process is shown in Creating a Model below. It does this by prompting the user to speak a phrase and passing the speech data to the MinHMM API to create an initial model for the phrase. Within MinHMM the front end processing converts audio sampled data into a representation of the signal. When the audio activity detector locates speech it triggers the creation of the model. A delay provides compensation for the time it takes the activity detector to respond. The created model is stored in model memory. This process must be repeated to create each phrase model to be recognized. The MinHMM library provides APIs to check the duration of a potential model and a quality measure that provides an estimate of how well the model will perform. These can be used by an application to choose to actually create the model, or guide the user to provide a better model.
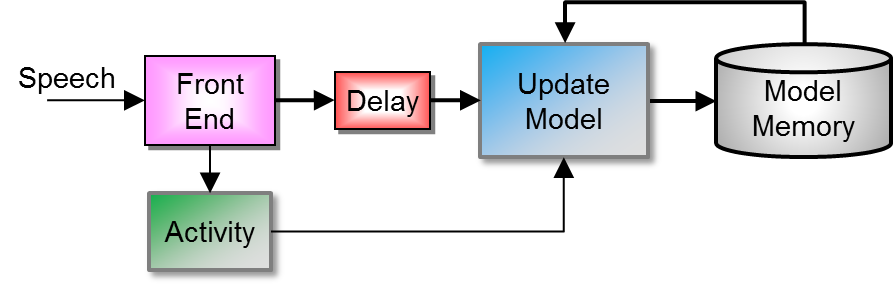
The application can update a specific model by prompting the user for the phrase to update and then to speak that phrase again. The speech data is passed to the MinHMM API to update the phrase model. The processing, as shown in Updating a Model below is similar to creating a model, except that the phrase model is retrieved from memory and merged with the new speech data to provide an improved model. Updating the model can be performed any number of times to further improve the model. Typically at least two or three updates should be performed.
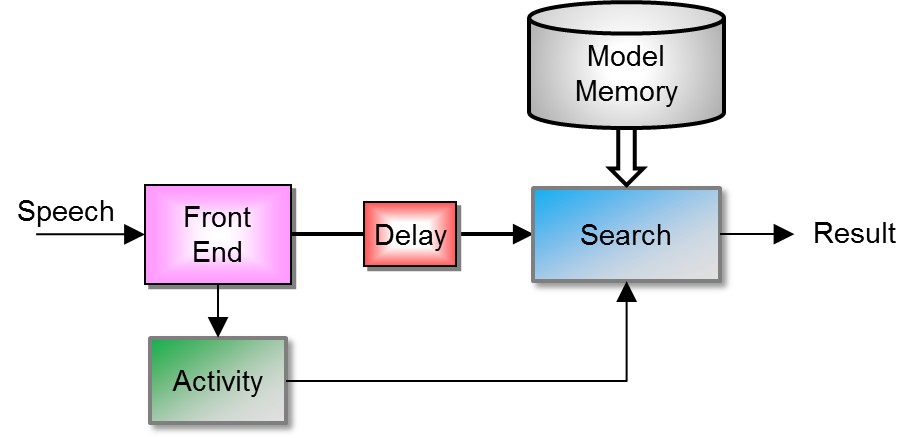
The application uses MinHMM with the trained models to perform recognition of the phrases as shown in Recognizing Speech. The application does this by capturing audio data and passing it to the MinHMM API that searches for the presence of the trained phrases in the audio data. Upon locating one of the phrases in the audio data, MinHMM notifies the application. After notification, the application can take action based on the recognition result. It can also use MinHMM APIs to immediately continue the recognition search for another phrase.
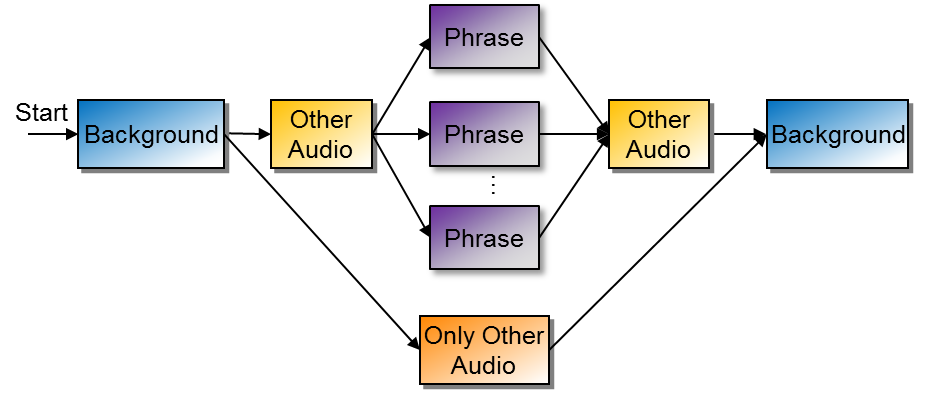
The MinHMM recognizer searches the incoming audio data for occurrences of one of the phrase models. Search Engine Block Diagram below illustrates how MinHMM performs the search. Search starts when the audio activity detector finds a signal other than background noise. Due to delay, the audio signal at the beginning of the search contains a small amount of background noise. At the end of the initial background noise the search engine checks for an audio signal of any duration that does not match any of the model phrases, for example some speech other than the model phrases. It then searches for speech that matches one of the model phrases. At the same time, as illustrated at the bottom of the figure, it also searches for an audio signal that does not contain any of the model phrases. The search engine also determines if there is additional audio after one of the model phrases. The search will terminate when the input signal returns to background noise, or, depending on option settings it may terminate when it finds the end of a portion of the signal corresponding to one of the model phrases. There are several options for search that are described in Run-time Options.