|
TI Deep Learning Product User Guide
|
|
TI Deep Learning Product User Guide
|
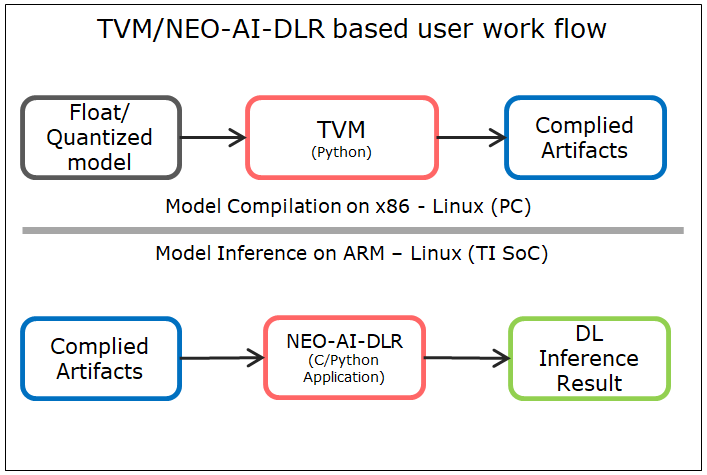
The Processor SDK implements TIDL offload support using the TVM runtime and Neo-AI-DLR runtime. This heterogeneous execution enables:
Neo-AI-DLR is an open source common runtime for machine learning models compiled by AWS SageMaker Neo, TVM, or Treelite. For the Processor SDK, we focus on models compiled by TVM. For these models, the Neo-AI-DLR runtime can be considered as a wrapper around the TVM runtime.
The following sections describe the details for compiling and deploying machine learning models for TVM/Neo-AI-DLR + TIDL heterogeneous execution.
The diagram below illustrates TVM/NEO-AI-DLR based work flow. The user needs to run the model compilation (sub-graph(s) creation and quantization) on PC and the generated artifacts can be used for inference on the device.

The Processor SDK package includes all the required python packages for runtime support.
Pre-requisite : PSDK RA should be installed on the Host Ubuntu 18.04 machine and able to run pre-built demos on EVM.
Following steps need to be followed : (Note - All below scripts to be run from ${PSDKRA_PATH}/tidl_xx_xx_xx_xx/ti_dl/test/tvm-dlr/ folder)
Note
This scripts downalod the TVM and DLR python packages from latest PSDK release in the ti.com If you are using diffrent version of SDK (Example RC versions), then please update links for these two python whl files in the download_models.py - 'dlr-1.4.0-py3-none-any.whl' : {'url':'http://swubn03.india.englab.ti.com/webgen/publish/PROCESSOR-SDK-LINUX-J721E/07_02_00_05/exports//dlr-1.4.0-py3-none-any.whl', 'dir':'./'} If you observe any issue in pip. Run below command to update pippython -m pip install --upgrade pip
The artifacts generated by python scripts in the above section can be inferred using either python or C/C++ APIs. The following steps are for running inference using python API. Refer Link for usage of C APIs for the same
Note : These scripts are only for basic functionally testing and performance check. Accuracy of the models can be benchmarked using the python module released here edgeai-benchmark
We also have IPython Notebooks for running inference on EVM. More details on this can be found here Link
There are only 4 lines that are specific to TIDL offload in TVM+TIDL compilation scripts. The rest of the script is no different from a regular TVM compilation script without TIDL offload.
tidl_compiler = tidl.TIDLCompiler(platform="J7", version="7.3",
tidl_tools_path=get_tidl_tools_path(),
artifacts_folder=tidl_artifacts_folder,
tensor_bits=8,
max_num_subgraphs=max_num_subgraphs,
deny_list=args.denylist,
accuracy_level=1,
advanced_options={'calibration_iterations':10}
)
We first instantiate a TIDLCompiler object. The parameters are explained in the following table.
| Name/Position | Value |
|---|---|
| platform | "J7" |
| version | "7.3" |
| tidl_tools_path | set to environment variable TIDL_TOOLS_PATH, usually psdk_rtos_install/tidl_xx_yy_zz_ww/ti_dl/tidl_tools |
| artifacts_folder | where to store deployable module |
| Optional Parameters | |
| tensor_bits | 8 or 16 for import TIDL tensor and weights, default is 8 |
| debug_level | 0, 1, 2, 3, 4 for various debug info, default is 0 |
| max_num_subgraphs | offload up to <num> tidl subgraphs, default is 16 |
| deny_list | deny TVM relay ops for TIDL offloading, comma separated string, default is "" |
| accuracy_level | 0 for simple calibration, 1 for advanced bias calibration, 9 for user defined, default is 1 |
| ti_internal_nc_flag | internal use only , default is 0x641 |
| advanced_options | a dictionary to overwrite default calibration options, default is {} |
| advanced_options Keys | (if not specified, defaults are used) |
| 'calibration_iterations' | number of calibration iterations , default is 50 |
| 'quantization_scale_type' | 0 for non-power-of-2, 1 for power-of-2, default is 0 |
| 'high_resolution_optimization' | 0 for disable, 1 for enable, default is 0 |
| 'pre_batchnorm_fold' | 0 for disable, 1 for enable, default is 1 |
| 'output_feature_16bit_names_list' | comma separated string, default is "" |
| 'params_16bit_names_list' | comma separated string, default is "" |
| (below are overwritable at accuracy level 9 only) | |
| 'activation_clipping' | 0 for disable, 1 for enable |
| 'weight_clipping' | 0 for disable, 1 for enable |
| 'bias_calibration' | 0 for disable, 1 for enable |
| 'channel_wise_quantization' | 0 for disable, 1 for enable |
Advanced calibration can help improve 8-bit quantization. Please see TIDL Quantization for details. Default advanced options are specified in tvm source file, python/tvm/relay/backend/contrib/tidl.py. Please grep for "default_advanced_options".
mod, status = tidl_compiler.enable(mod_orig, params, model_input_list)
In this step, the original machine learning model/network represented in TVM Relay IR, "mod_orig", goes through the following transformations:
with tidl.build_config(tidl_compiler=tidl_compiler):
graph, lib, params = relay.build_module.build(mod, target=target, params=params)
In this step, TVM code generation takes place. Inside the TVM codegen, there is a TIDL codegen backend. "tidl.build_config" creates a context and tells the TIDL codegen backend where the artifacts from TIDL importing are. The backend then embeds the artifacts into the "lib".
tidl.remove_tidl_params(params)
This optional step removes the weights in TIDL subgraphs that have already been imported into the artifacts. Removing them results in a smaller deployable module.
NEO-AI-DLR on the EVM/Target supports both Pythin and C-API. This section of describes the usage of C-API
Pre-requisite: Compiled artifacts stored in artifacts folder as specified in step 2 of 'Model Compilation on PC' above.
Following steps are needed to run C API based demo for DLR runtime. Note : This is only an example C API demo, user may need to modify code for using other models and images.
cd ${PSDKRA_PATH}
export PSDK_INSTALL_PATH=$(pwd)
cd targetfs/usr/lib/
ln -s libtbb.so.2 libtbb.so
ln -s libtiff.so.5 libtiff.so
ln -s libwebp.so.7 libwebp.so
ln -s libopencv_highgui.so.4.1 libopencv_highgui.so
ln -s libopencv_imgcodecs.so.4.1 libopencv_imgcodecs.so
ln -s libopencv_core.so.4.1.0 libopencv_core.so
ln -s libopencv_imgproc.so.4.1.0 libopencv_imgproc.so
cd ../../../tidl_j7_xx_xx_xx_xx
make demos DIRECTORIES=dlr
# To run on EVM:
Mount ${PSDKR_PATH} on EVM
export LD_LIBRARY_PATH=/usr/lib
cd ${PSDKR_PATH}/tidl_j7_xx_xx_xx_xx/ti_dl/demos/out/J7/A72/LINUX/release/
./tidl_tdlr_classification.out -m ../../../../../../test/testvecs/models/public/tflite/mobilenet_v1_1.0_224.tflite -l ../../../../../../test/testvecs/input/labels.txt -i ../../../../../../test/testvecs/input/airshow.bmp
The result of compilation is called a "deployable module". It consists of three files:
Taking the output of "tvm-compilation-onnx-example.py" for ONNX MobilenetV2 for example, the deployable module for J7 target is located in "onnx_mobilenetv2/". You can copy this deployable module to the target EVM for execution. Please see the above "Run Model on EVM" section for details.
onnx_mobilenetv2 |-- deploy_graph.json |-- deploy_lib.so |-- deploy_param.params
All other compilation artifacts are stored in the "tempDir" directory under the specified "artifacts_folder". Interested users can look into this directory for TIDL importing details. This directory is for information only, and is not needed for inference/deployment.
One useful file is "relay.gv.svg". It gives a graphical view of the whole network and where the TIDL subgraphs are. You can view it using a browser or other viewer, for example:
firefox onnx_mobilenetv2/tempDir/relay.gv.svg
You can set the TIDLCompiler parameter "debug_level" to 0, 1, 2, 3, or 4 for detailed internal debug information and progress during TVM compilation. For example the compiler will dump the graph represented in TVM Relay IR, RelayIR to TIDL importing, etc.
When "debug_level" is set to 4, TIDL import will generate the output for each TIDL layer in the imported TIDL subgraph, using calibration inputs. The compilation will also generate corresponding output from running the original model in floating point mode, by compiling and running on the host using TVM. We name the tensors from TIDL quantized calibration execution "tidl_tensor"; we name the corresponding tensors from TVM floating point execution "tvm_tensor". A simple script, "compare_tensors.py", is provided to compare these two tensors.
python3 ./tvm-compilation-onnx-example.py # with TIDLCompiler(...,debug_level=4) # python3 ./compare_tensors.py <artifacts_folder> <subgraph_id> <layer_id> python3 ./compare_tensors.py onnx_mobilentv2 0 1
TVM compilation flow can accept multiple network formats in various Open Source Runtime formats. The following are the list of known compataible OSRT python package versions that we have tested with the PSDK TVM compilation flow.
| Python Package Name | Version Compatible with PSDK TVM |
|---|---|
| tflite | 2.4.0 |
| onnx | 1.9.0 |
| mxnet | 1.7.0.post2 |
| gluoncv | 0.8.0 |
| torch | 1.7.0 |
| torchvision | 0.8.1 |
| tensorflow | 1.14.0 |
 1.8.14
1.8.14