|
TI Deep Learning Product User Guide
|
|
TI Deep Learning Product User Guide
|
TIDL implements sub-graph offload to TIDL-RT using the ONNX runtime Onnx runtime.
This heterogeneous execution enables:
The diagram below illustrates an ONNX runtime based workflow. The User needs to run the model compilation (sub-graph(s) creation and quantization) on PC and the generated artifacts can be used for inference on the device.
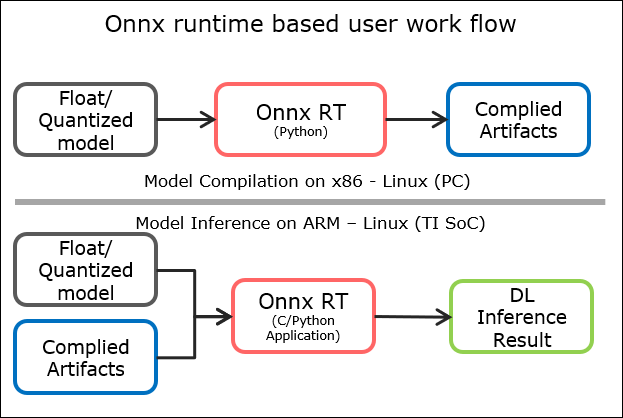

The Processor SDK package includes all the required python packages for runtime support.
Pre-requisite : PSDK RA should be installed on the Host Ubuntu 18.04 machine and able to run pre-built demos on EVM.
The following steps need to be done : (Note - All the scripts below need to be run from the ${PSDKRA_PATH}/tidl_xx_xx_xx_xx/ti_dl/test/onnxrt/ folder)
- Install all the python dependent packages like ONNX-runtime, numPy, Python image library (Pillow) etc. If user has a conflicting package version because of other installations, we recommend to create conda environment with python 3.6.x and run these scripts. - Download the models used by the OOB scripts if not available in the file system. - Set the environment variables required by the script e.g. path to tools and shared libraries. - Checks if all the TIDL required tools are available in tools path.
Note
If you observe any issue in pip. Run the command below to update pippython -m pip install --upgrade pip
The artifacts generated by python scripts in the above section can inferenced using either python or C/C++ APIs. The following steps are for running inference using python API. Refer Link for usage of C APIs for the same
Note : These scripts are only for basic functionally testing and performance check. Accuracy of the models can be benchmarked using the python module released here edgeai-benchmark
We also have Ipython Notebooks for running inference on EVM. More details on the can be found here Link
An example call to onnx runtime session from the python interface :
EP_list = ['TIDLExecutionProvider','CPUExecutionProvider']
sess = rt.InferenceSession('path_to_model' ,providers=EP_list, provider_options=[delegate_options, {}], sess_options=so)
'delegate_options' in the inference session call comprise of the following options (required and optional):
The following options need to be specified by the user while creating an ONNX runtime session:
| Name | Value |
|---|---|
| tidl_tools_path | to be set to ${PSDKRA_PATH}/tidl_xx_xx_xx_xx/tidl_tools/ - Path from where to pick TIDL related tools |
| artifacts_folder | folder where user intends to store all the compilation artifacts |
The following options are set to default values, to be specified if modification is needed by user. Below optional arguments are specific to model compilation and not applicable to inference except the 'debug_level'
| Name | Description | |
|---|---|---|
| platform | "J7" | "J7" |
| version | TIDL version - open source runtimes supported from version 7.2 onwards | (7,3) |
| tensor_bits | Number of bits for TIDL tensor and weights - 8/16 | 8 |
| debug_level | 0 - no debug, 1 - rt debug prints, >=2 - increasing levels of debug and trace dump | 0 |
| max_num_subgraphs | offload up to <num> tidl subgraphs [^2] | 16 |
| deny_list | force disable offload of a particular operator to TIDL [^3] | "" - Empty list |
| accuracy_level | 0 - basic calibration, 1 - higher accuracy(advanced bias calibration), 9 - user defined [^4] | 1 |
| advanced_options:calibration_frames | Number of frames to be used for calibration - min 10 frames recommended | 20 |
| advanced_options:calibration_iterations | Number of bias calibration iterations [^1] | 50 |
| advanced_options:output_feature_16bit_names_list | List of names of the layers (comma separated string) as in the original model whose feature/activation output user wants to be in 16 bit [^1] [^5] | "" |
| advanced_options:params_16bit_names_list | List of names of the output layers (separated by comma or space or tab) as in the original model whose parameters user wants to be in 16 bit [^1] [^6] | "" |
| advanced_options:quantization_scale_type | 0 for non-power-of-2, 1 for power-of-2 | 0 |
| advanced_options:high_resolution_optimization | 0 for disable, 1 for enable | 0 |
| advanced_options:pre_batchnorm_fold | Fold batchnorm layer into following convolution layer, 0 for disable, 1 for enable | 1 |
| advanced_options:add_data_convert_ops | Adds the Input and Output format conversions to Model and performs the same in DSP instead of ARM. This is currently a experimental feature. | 0 |
| object_detection:meta_layers_names_list | Path to meta architecture prototxt file for OD models [^7] | "" |
| object_detection:meta_arch_type | Type of OD model post processing [^7] | -1 |
| ti_internal_nc_flag | internal use only | - |
| ti_internal_reserved_1 | internal use only for onnxrt | - |
Below options will be overwritten only if accuracy_level = 9, else will be discarded. For accuracy level 9, specified options will be overwritten, rest will be set to default values. For accuracy_level = 0/1, these are preset internally.
| Name | Description | Default values |
|---|---|---|
| advanced_options:activation_clipping | 0 for disable, 1 for enable [^1] | 1 |
| advanced_options:weight_clipping | 0 for disable, 1 for enable [^1] | 1 |
| advanced_options:bias_calibration | 0 for disable, 1 for enable [^1] | 1 |
| advanced_options:channel_wise_quantization | 0 for disable, 1 for enable [^1] | 0 |
[^1]: Advanced calibration can help improve 8-bit quantization. Please see TIDL Quantization for details.
[^2]: Will be supported in next release
[^3]: Denylist is a comma separated string of operator types as defined by onnx runtime e.g. deny_list = "MaxPool, Concat" to deny offloading ''MaxPool' and 'Concat' operators to TIDL.
[^4]: Advanced calibration options can be specified by setting accuracy_level = 9.
[^5]: Note that if for a given layer feature/activations is in 16 bit then parameters will automatically become 16 bit and user need not specify them as part of "advanced_options:params_16bit_names_list". Example format - "conv1_2, fire9/concat_1"
[^6]: This is not the name of the parameter of the layer but is expected to be the output name of the layer. Note that, if a given layers feature/activations is in 16 bit then parameters will automatically become 16 bit even if its not part of this list
[^7]: Please refer [] for further details on running OD models through ONNX runtime
Pre-requisite: Compiled artifacts stored in artifacts folder as specified in step 2 of 'Model Compilation on PC' above.
Following steps are needed to run C API based demo for onnx runtime. Note : This is only an example C API demo, user may need to modify code for using other models and images.
cd ${PSDKRA_PATH}
git clone https://github.com/microsoft/onnxruntime
cd onnxruntime
git checkout c8e2e3191b2d506d1260069eb3d3fc7c262ec172
git am ../tidl_j7_xx_xx_xx_xx/ti_dl/onnxrt_EP/0001-Add-TIDL-compilation-execution-providers.patch
cd ..
export PSDK_INSTALL_PATH=$(pwd)
cd targetfs/usr/lib/
ln -s libonnxruntime.so.1.7.0 libonnxruntime.so
ln -s libtbb.so.2 libtbb.so
ln -s libtiff.so.5 libtiff.so
ln -s libwebp.so.7 libwebp.so
ln -s libopencv_highgui.so.4.1 libopencv_highgui.so
ln -s libopencv_imgcodecs.so.4.1 libopencv_imgcodecs.so
ln -s libopencv_core.so.4.1.0 libopencv_core.so
ln -s libopencv_imgproc.so.4.1.0 libopencv_imgproc.so
cd ../../../tidl_j7_xx_xx_xx_xx
make demos DIRECTORIES=onnx
# To run on EVM:
Mount ${PSDKR_PATH} on EVM
export LD_LIBRARY_PATH=/usr/lib
cd ${PSDKR_PATH}/tidl_j7_xx_xx_xx_xx/ti_dl/demos/out/J7/A72/LINUX/release/
./tidl_onnx_classification.out ../../../../../../test/testvecs/input/airshow_224x224.bmp ../../../../../../test/testvecs/models/public/onnx/resnet18-v1-7.onnx ../../../../../../test/testvecs/input/labels.txt -t
 1.8.14
1.8.14