- Convolution neural network (CNN) based Machine learning algorithms are used in many ADAS applications and self-driving cars. These algorithms are defined in the form of network structure with thousands of parameters. These algorithms need to be accelerated on TI devices (with C6x and C7x DSP core) without much effort from the algorithm developer/customer
- Interoperability: There are many tools/frameworks available in PC for algorithm development (Training and fine-tuning). We need to have a solution to support most of these popular frameworks in TI devices with optimal resource utilization.
- High Compute: The MAC requirements of these CNN networks are in the range of 500 Giga MACs to 10 Tera MACs for 1 MP image real-time processing. TI Jacinto7 automotive processors/ SoCs can deliver 4 to 10 TOPs for CNN algorithms.
- High Memory Bandwidth: CNN networks normally consist of multiple layers (20 to 100s), each of these layers have multiple channels (around 4 Mbytes output from each layer). As we understand the embedded devises have limited memory bandwidth and it plays an important role in device compute utilization.
- Scalability :
- API : The algorithms (layers) used in these CNN networks are evolving, there are many layers are getting defined in continuously. The interface and data flow shall be scalable to add any new layers. -Performance: TI devices have multiple compute cores (C6x and C7x DSP) in each SoC. The solutions shall be scalable to utilize these core simultaneously without much effort from users
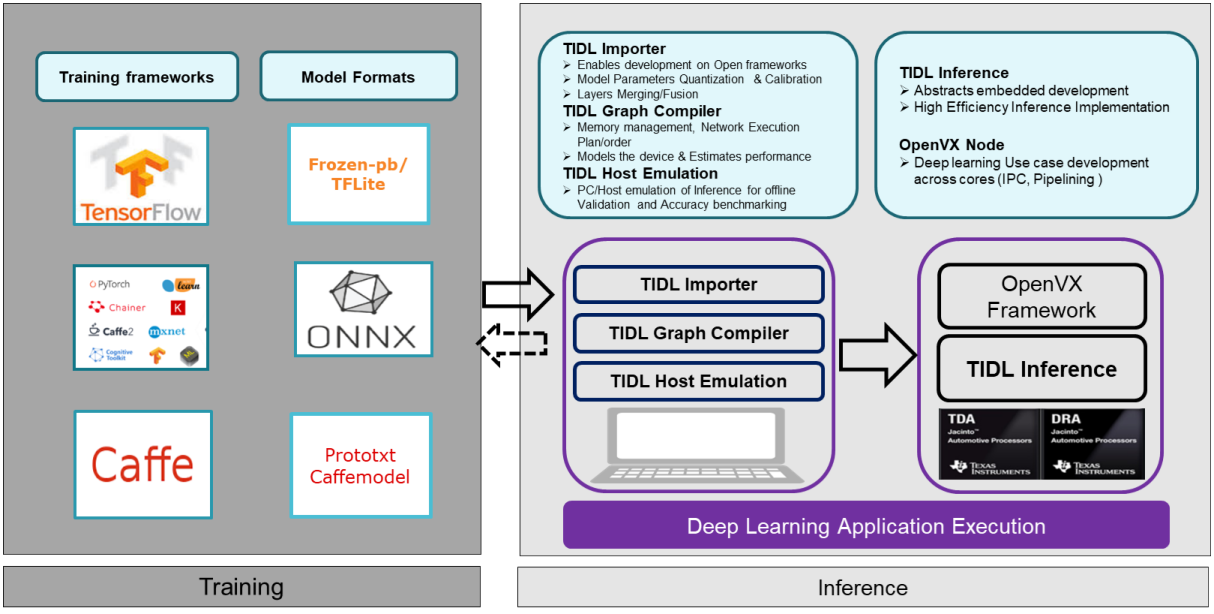
Fundamental blocks of TI Deep Learning Library
The TI Deep Learning Library addresses the above-mentioned problems with following solutions
- Extendable API (Using XDAIS compliant API) and software architecture to allow integration of newer layers
- Appropriate usage of memory hierarchy and data flow to optimally utilize the memory bandwidth at DDR and L2, MSMC
 1.8.14
1.8.14