3. Edge AI sample apps¶
There are 3 ways you can explore running a typical camera-inference-display Edge AI usecase on AM68A EVM,
Trying the out-of-box Edge AI gallery application
Develop Edge AI applications using Python and C++ reference examples
Run ‘No Code’ optimized end-to-end GStreamer applications - OpTIFlow
The SDK is packaged with networks which does 3 DL tasks as below,
Image Classification: Detects top 5 most approximate classes in the Imagenet dataset for the given input frame
Object Detection: Detects and draws bounding boxes around the objects, also classifies the objects to one of the classes in coco dataset
Semantic Segmentation: Classifies each pixel into class in ade20k dataset
3.1. Out-of-box GUI app¶
When the AM68A EVM is powered on with SD card in place, the Edge AI Gallery Application comes up on boot as shown. One can connect a USB 2.0 mouse and click on the buttons in the left panel which starts the Edge AI application running the selected DL task. In the background, a GStremer pipeline is launched which reads a compressed video file and runs a DL network on the decoded content. The output of DL inference is overlayed on the image and sent to display.

Users can select different DL tasks to execute on the compressed video. There is also a “Custom” button, which when pressed can select the input source, which can a compressed video file (H.264/H.265), USB camera or IMX219 camera. One can also select from a list of pre-imported DL networks available in the filesystem and start the application. This will automatically construct a GStreamer pipeline with required elements and launch the application.
3.2. Python/C++ apps¶
Python based demos are simple executable scripts written for image classification, object detection and semantic segmentation. Demos are configured using a YAML file. Details on configuration file parameters can be found in Configuring applications
Sample configuration files for out of the box demos can be found in
edgeai-gst-apps/configs this folder also contains a template config file
which has brief info on each configurable parameter edgeai-gst-apps/configs/app_config_template.yaml
Here is how a Python based image classification demo can be run,
/opt/edgeai-gst-apps/apps_python# ./app_edgeai.py ../configs/image_classification.yaml
The demo captures the input frames from connected USB camera and passes through pre-processing, inference and post-processing before sent to display. Sample output for image classification and object detection demos are as below,
|
|


To exit the demo press Ctrl+C.
C++ apps are cross compiled while packaging, they can be directly tested as given below
/opt/edgeai-gst-apps/apps_cpp# ./bin/Release/app_edgeai ../configs/image_classification.yaml
To exit the demo press Ctrl+C.
C++ apps can be modified and built on the target as well using below steps
/opt/edgeai-gst-apps/apps_cpp# rm -rf build bin lib
/opt/edgeai-gst-apps/apps_cpp# mkdir build
/opt/edgeai-gst-apps/apps_cpp# cd build
/opt/edgeai-gst-apps/apps_cpp/build# cmake ..
/opt/edgeai-gst-apps/apps_cpp/build# make -j2
Note
Both Python and C++ applications are similar by construction and can accept the same config file and command line arguments
3.3. OpTIFlow¶
In Edge AI Python and C++ applications, post processing and DL inference are done between appsink and appsrc application boundaries. This makes the data flow sub-optimal because of unnecessary data format conversions to work with open source components.
This is solved by providing DL-inferer plugin which calls one of the supported DL runtime and a post-process plugin which works natively on NV12 format, avoiding unnecessary color formats conversions.
Users can write their own pipeline or use a helper script provided to generate the end-to-end pipeline. The provided helper script shares the same config file as used by Python/C++ apps. Running this script will print a readable end-to-end gstreamer pipeline which user can copy and modify if needed.
/opt/edgeai-gst-apps/script/optiflow# ./optiflow.py ../../configs/object_detection.yaml
To directly run the end-to-end pipeline use the following command.
/opt/edgeai-gst-apps/script/optiflow# `./optiflow.py ../../configs/object_detection.yaml -t`
Below are some examples which demonstrates an end-to-end pipeline. These pipelines can be copied as-is and launched on the target
Single Input Single Inference Pipeline
Below pipeline reads a video file, decode, perform DL inference, draw boxes on detected objects and display
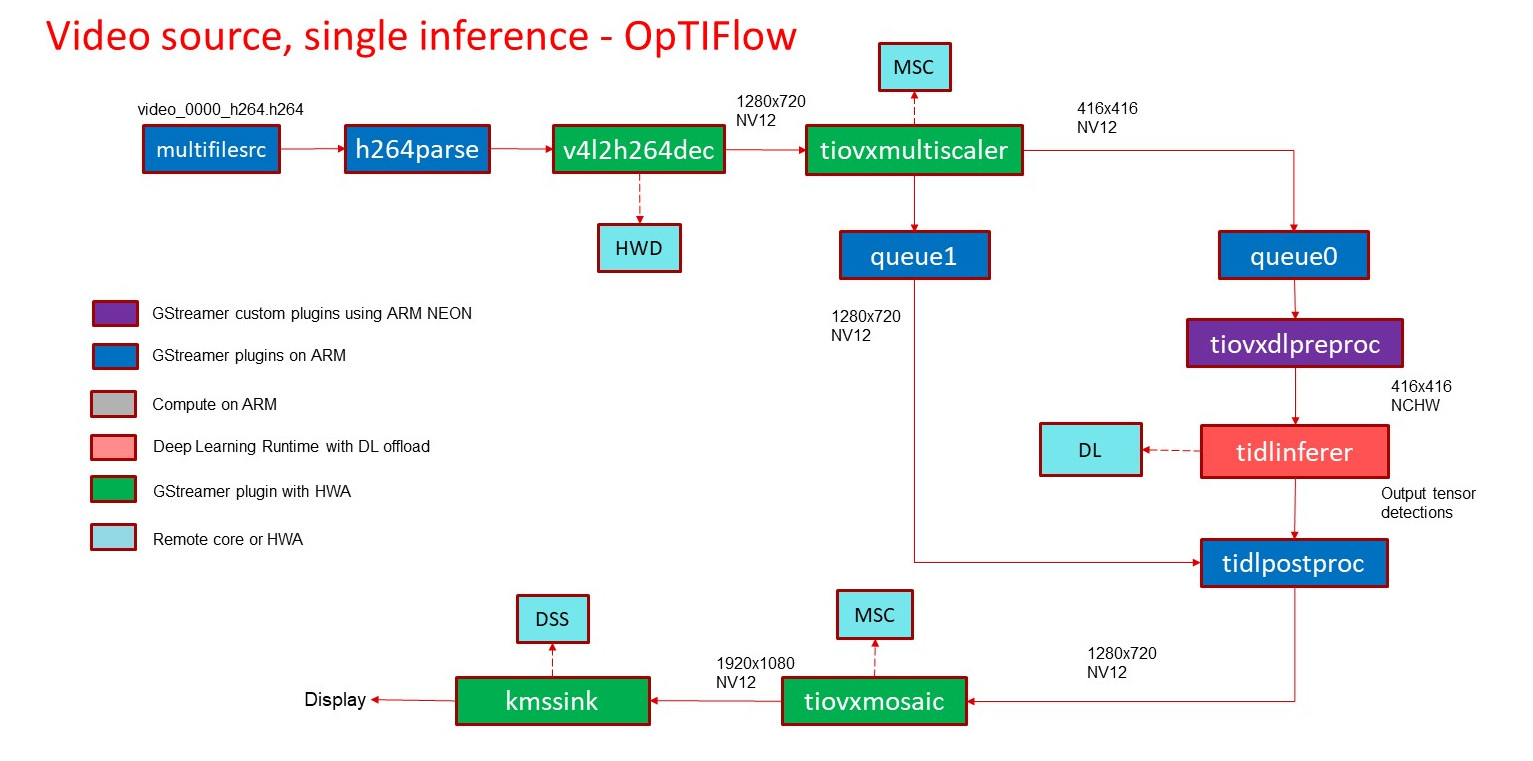
Fig. 3.1 Optimized data-flow for object detection with single video input, inference and display¶
gst-launch-1.0 \
multifilesrc location=/opt/edgeai-test-data/videos/video_0000_h264.h264 \
caps=video/x-h264,width=1280,height=720,framerate=30/1 ! \
h264parse ! v4l2h264dec ! tiovxmemalloc pool-size=8 ! \
video/x-raw, format=NV12 ! \
\
tiovxmultiscaler name=scale \
\
scale. ! queue ! video/x-raw, width=416, height=416 ! \
tiovxdlpreproc data-type=3 channel-order=0 tensor-format=bgr ! \
tidlinferer model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! \
queue ! post.tensor \
\
scale. ! queue ! post.sink \
\
tidlpostproc name=post model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! \
tiovxmosaic sink_0::startx="<320>" sink_0::starty="<150>" ! \
video/x-raw, width=1920, height=1080 ! queue ! \
tiperfoverlay title="Object Detection" ! kmssink sync=false driver-name=tidss force-modesetting=true
Single Input Multi Inference Pipeline
Below pipeline reads a video file, decode, perform 4 x DL inference, draw boxes on detected objects, composite and display
gst-launch-1.0 \
multifilesrc location=/opt/edgeai-test-data/videos/video_0000_h264.h264 \
caps=video/x-h264,width=1280,height=720,framerate=30/1 ! \
h264parse ! v4l2h264dec ! tiovxmemalloc pool-size=8 ! \
video/x-raw, format=NV12 ! \
tee name=split \
\
split. ! queue ! tiovxmultiscaler name=scale1 \
split. ! queue ! tiovxmultiscaler name=scale2 \
\
scale1. ! queue ! video/x-raw, width=416, height=416 ! \
tiovxdlpreproc data-type=3 channel-order=0 tensor-format=bgr ! \
tidlinferer model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! \
queue ! post1.tensor \
\
scale1. ! queue ! video/x-raw, width=640, height=360 ! post1.sink \
\
scale1. ! queue ! video/x-raw, width=454, height=256 ! tiovxdlcolorconvert ! video/x-raw, format=RGB ! \
videobox qos=True left=115 right=115 top=16 bottom=16 ! \
tiovxdlpreproc out-pool-size=4 channel-order=1 data-type=3 ! \
tidlinferer model=/opt/model_zoo/TVM-CL-3090-mobileNetV2-tv ! \
queue ! post2.tensor \
\
scale1. ! queue ! video/x-raw, width=640, height=360 ! post2.sink \
\
scale2. ! queue ! video/x-raw, width=512, height=512 ! \
tiovxdlpreproc out-pool-size=4 data-type=3 ! \
tidlinferer model=/opt/model_zoo/ONR-SS-8610-deeplabv3lite-mobv2-ade20k32-512x512 ! \
queue ! post3.tensor \
\
scale2. ! queue ! video/x-raw, width=640, height=360 ! post3.sink \
\
scale2. ! queue ! video/x-raw, width=320, height=320 ! \
tiovxmultiscaler ! video/x-raw,width=300,height=300 ! \
tiovxdlpreproc channel-order=1 data-type=3 ! \
tidlinferer model=/opt/model_zoo/TFL-OD-2010-ssd-mobV2-coco-mlperf-300x300 ! \
queue ! post4.tensor \
\
scale2. ! queue ! video/x-raw, width=640, height=360 ! post4.sink \
\
tidlpostproc name=post1 model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! mosaic. \
tidlpostproc name=post2 model=/opt/model_zoo/TVM-CL-3090-mobileNetV2-tv ! mosaic. \
tidlpostproc name=post3 model=/opt/model_zoo/ONR-SS-8610-deeplabv3lite-mobv2-ade20k32-512x512 ! mosaic. \
tidlpostproc name=post4 model=/opt/model_zoo/TFL-OD-2010-ssd-mobV2-coco-mlperf-300x300 ! mosaic. \
\
tiovxmosaic name=mosaic \
sink_0::startx="<320>" sink_0::starty="<180>" \
sink_1::startx="<960>" sink_1::starty="<180>" \
sink_2::startx="<320>" sink_2::starty="<560>" \
sink_3::startx="<960>" sink_3::starty="<560>" ! \
video/x-raw, width=1920, height=1080 ! queue ! \
tiperfoverlay title="Single Input Multi Inference" ! kmssink sync=false driver-name=tidss force-modesetting=true
Multi Input Multi Inference Pipeline
Below pipeline reads a video file and capture from USB Camera, perform 2 x DL inference on each stream, draw boxes over detected objects, composite and display
gst-launch-1.0 \
multifilesrc location=/opt/edgeai-test-data/videos/video_0000_h264.h264 \
caps=video/x-h264,width=1280,height=720,framerate=30/1 ! \
h264parse ! v4l2h264dec ! tiovxmemalloc pool-size=8 ! \
video/x-raw, format=NV12 ! \
tee name=input1 \
\
v4l2src device=/dev/video2 ! image/jpeg, width=1280, height=720 ! \
jpegdec ! tiovxdlcolorconvert ! video/x-raw, format=NV12 ! \
tee name=input2 \
\
input1. ! queue ! tiovxmultiscaler name=scale1 \
input2. ! queue ! tiovxmultiscaler name=scale2 \
\
scale1. ! queue ! video/x-raw, width=416, height=416 ! \
tiovxdlpreproc data-type=3 channel-order=0 tensor-format=bgr ! \
tidlinferer model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! \
queue ! post1.tensor \
\
scale1. ! queue ! video/x-raw, width=640, height=360 ! post1.sink \
\
scale1. ! queue ! video/x-raw, width=454, height=256 ! tiovxdlcolorconvert ! video/x-raw, format=RGB ! \
videobox qos=True left=115 right=115 top=16 bottom=16 ! \
tiovxdlpreproc out-pool-size=4 channel-order=1 data-type=3 ! \
tidlinferer model=/opt/model_zoo/TVM-CL-3090-mobileNetV2-tv ! \
queue ! post2.tensor \
\
scale1. ! queue ! video/x-raw, width=640, height=360 ! post2.sink \
\
scale2. ! queue ! video/x-raw, width=512, height=512 ! \
tiovxdlpreproc out-pool-size=4 data-type=3 ! \
tidlinferer model=/opt/model_zoo/ONR-SS-8610-deeplabv3lite-mobv2-ade20k32-512x512 ! \
queue ! post3.tensor \
\
scale2. ! queue ! video/x-raw, width=640, height=360 ! post3.sink \
\
scale2. ! queue ! video/x-raw, width=320, height=320 ! \
tiovxmultiscaler ! video/x-raw,width=300,height=300 ! \
tiovxdlpreproc channel-order=1 data-type=3 ! \
tidlinferer model=/opt/model_zoo/TFL-OD-2010-ssd-mobV2-coco-mlperf-300x300 ! \
queue ! post4.tensor \
\
scale2. ! queue ! video/x-raw, width=640, height=360 ! post4.sink \
\
tidlpostproc name=post1 model=/opt/model_zoo/ONR-OD-8200-yolox-nano-lite-mmdet-coco-416x416 ! mosaic. \
tidlpostproc name=post2 model=/opt/model_zoo/TVM-CL-3090-mobileNetV2-tv ! mosaic. \
tidlpostproc name=post3 model=/opt/model_zoo/ONR-SS-8610-deeplabv3lite-mobv2-ade20k32-512x512 ! mosaic. \
tidlpostproc name=post4 model=/opt/model_zoo/TFL-OD-2010-ssd-mobV2-coco-mlperf-300x300 ! mosaic. \
\
tiovxmosaic name=mosaic \
sink_0::startx="<320>" sink_0::starty="<180>" \
sink_1::startx="<960>" sink_1::starty="<180>" \
sink_2::startx="<320>" sink_2::starty="<560>" \
sink_3::startx="<960>" sink_3::starty="<560>" ! \
video/x-raw, width=1920, height=1080 ! queue ! \
tiperfoverlay title="Multi Input Multi Inference" ! kmssink sync=false driver-name=tidss force-modesetting=true
Note
Remove force-modesetting=true from kmssink if the fps needs to be capped to 30.