10.5.5. The SECTIONS Directive¶
After you use MEMORY to specify the target system’s memory model, you can use SECTIONS to allocate output sections into specific named memory ranges or into memory that has specific attributes. For example, you could allocate the .text and .data sections into the area named FAST_MEM and allocate the .bss section into the area named SLOW_MEM.
The SECTIONS directive controls your sections in the following ways:
Describes how input sections are combined into output sections
Defines output sections in the executable program
Allows you to control where output sections are placed in memory in relation to each other and to the entire memory space (Note that the memory placement order is not simply the sequence in which sections occur in the SECTIONS directive unless the –honor_cmdfile_order option is used.)
Permits renaming of output sections
For more information, see How the Linker Handles Sections, Symbolic Relocations, and Subsections. Subsections allow you to manipulate sections with greater precision.
If you do not specify a SECTIONS directive, the linker uses a default algorithm for combining and allocating the sections. Default Placement Algorithm describes this algorithm in detail.
10.5.5.1. SECTIONS Directive Syntax¶
The SECTIONS directive is specified in a command file by the word SECTIONS (uppercase), followed by a list of output section specifications enclosed in braces.
The general syntax for the SECTIONS directive is:
SECTIONS
{
name : [property [, property] [, property] ... ]
name : [property [, property] [, property] ... ]
name : [property [, property] [, property] ... ]
}
Each section specification, beginning with name, defines an output section. (An output section is a section in the output file.) Section names can refer to sections, subsections, or archive library members. (See Using Multi-Level Subsections for information on multi-level subsections.) After the section name is a list of properties that define the section’s contents and how the section is allocated. The properties can be separated by optional commas. Possible properties for a section are as follows:
- Load allocation¶
Defines where in memory the section is to be loaded. See Run-Time Relocation, Load and Run Addresses, and Placing a Section at Different Load and Run Addresses.
Syntax:
load = allocation
or
> allocation
- Run allocation¶
Defines where in memory the section is to be run.
Syntax:
run = allocation
or
run > allocation
- Input sections¶
Defines the input sections (object files) that constitute the output section. See Specifying Input Sections.
Syntax:
{ input_sections }
- Section type¶
Defines flags for special section types. See Special Section Types (DSECT, COPY, NOLOAD, and NOINIT).
Syntax:
type = COPY
or
type = DSECT
or
type = NOLOAD
- Fill value¶
Defines the value used to fill uninitialized holes. See Creating and Filling Holes.
Syntax:
fill = value
The following example shows a SECTIONS directive in a sample linker command file.
/**************************************************/
/* Sample command file with SECTIONS directive */
/**************************************************/
file1.c.o file2.c.o /* Input files */
--output_file=prog.out /* Options */
SECTIONS
{
.text: load = EXT_MEM, run = 0x00000800
.const: load = FAST_MEM
.rodata: load = FAST_MEM
.bss: load = SLOW_MEM
.vectors: load = 0x00000000
{
t1.c.o(.intvec1)
t2.c.o(.intvec2)
endvec = .;
}
.data:alpha: align = 16
.data:beta: align = 16
}
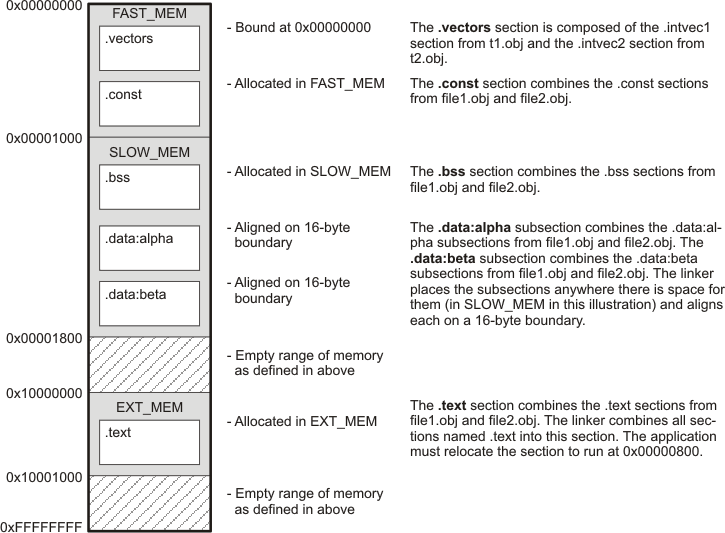
The following figure shows the output sections defined by the SECTIONS directive in the previous example (.vectors, .text, .const, .rodata, .bss, .data:alpha, and .data:beta) and shows how these sections are allocated in memory using the MEMORY directive given in MEMORY Directive Syntax.
10.5.5.2. Section Allocation and Placement¶
The linker assigns each output section two locations in target memory: the location where the section will be loaded and the location where it will be run. Usually, these are the same, and you can think of each section as having only a single address. The process of locating the output section in the target’s memory and assigning its address(es) is called placement. For more information about using separate load and run placement, see Placing a Section at Different Load and Run Addresses.
If you do not tell the linker how a section is to be allocated, it uses a default algorithm to place the section. Generally, the linker puts sections wherever they fit into configured memory. You can override this default placement for a section by defining it within a SECTIONS directive and providing instructions on how to allocate it.
You control placement by specifying one or more allocation parameters. Each parameter consists of a keyword, an optional equal sign or greater-than sign, and a value optionally enclosed in parentheses. If load and run placement are separate, all parameters following the keyword LOAD apply to load placement, and those following the keyword RUN apply to run placement. The allocation parameters are:
Binding |
allocates a section at a specific address.
|
Named memory |
allocates the section into a range defined in
the MEMORY directive with the specified name
(like SLOW_MEM) or attributes.
|
Alignment |
uses the align or palign keyword to specify the
section must start on an address boundary.
|
Blocking |
uses the block keyword to specify the section
must fit between two address aligned to the
blocking factor. If a section is too large, it
starts on an address boundary.
|
For the load (usually the only) allocation, use a greater-than sign and omit the load keyword:
.text: > SLOW_MEM.text: {...} > SLOW_MEM .text: > 0x4000
If more than one parameter is used, you can string them together as follows:
.text: > SLOW_MEM align 16
Or if you prefer, use parentheses for readability:
.text: load = (SLOW_MEM align(16))
You can also use an input section specification to identify the sections from input files that are combined to form an output section. See Specifying Input Sections.
10.5.5.2.1. Binding¶
You can set the starting address for an output section by following the section name with an address:
.text: 0x00001000
This example specifies that the .text section must begin at location 0x1000. The binding address must be a 32-bit constant.
Output sections can be bound anywhere in configured memory (assuming there is enough space), but they cannot overlap. If there is not enough space to bind a section to a specified address, the linker issues an error message.
Note
Binding is Incompatible With Alignment and Named Memory You cannot bind a section to an address if you use alignment or named memory. If you try to do this, the linker issues an error message.
10.5.5.2.2. Named Memory¶
You can allocate a section into a memory range that is defined by the MEMORY directive (see The MEMORY Directive). This example names ranges and links sections into them:
MEMORY
{
SLOW_MEM (RIX) : origin = 0x00000000, length = 0x00001000
FAST_MEM (RWIX) : origin = 0x03000000, length = 0x00000300
}
SECTIONS
{
.text :> SLOW_MEM
.data :> FAST_MEM ALIGN(128)
.bss:> FAST_MEM
}
In this example, the linker places .text into the area called SLOW_MEM. The .data and .bss output sections are allocated into FAST_MEM. You can align a section within a named memory range; the .data section is aligned on a 128-byte boundary within the FAST_MEM range.
Similarly, you can link a section into an area of memory that has particular attributes. To do this, specify a set of attributes (enclosed in parentheses) instead of a memory name. Using the same MEMORY directive declaration, you can specify:
SECTIONS
{
.text: > (X) /* .text --> executable memory*/
.data: > (RI) /* .data --> read or init memory */
.bss : > (RW) /* .bss --> read or write memory */
}
In this example, the .text output section can be linked into either the SLOW_MEM or FAST_MEM area because both areas have the X attribute. The .data section can also go into either SLOW_MEM or FAST_MEM because both areas have the R and I attributes. The .bss output section, however, must go into the FAST_MEM area because only FAST_MEM is declared with the W attribute.
You cannot control where in a named memory range a section is allocated, although the linker uses lower memory addresses first and avoids fragmentation when possible. In the preceding examples, assuming no conflicting assignments exist, the .text section starts at address 0. If a section must start on a specific address, use binding instead of named memory.
10.5.5.2.3. Controlling Placement Using The HIGH Location Specifier¶
The linker allocates output sections from low to high addresses within a designated memory range by default. Alternatively, you can cause the linker to allocate a section from high to low addresses within a memory range by using the HIGH location specifier in the SECTION directive declaration. You might use the HIGH location specifier in order to keep RTS code separate from application code, so that small changes in the application do not cause large changes to the memory map.
For example, given this MEMORY directive:
MEMORY
{
RAM : origin = 0x0200, length = 0x0800
FLASH : origin = 0x1100, length = 0xEEE0
VECTORS : origin = 0xFFE0, length = 0x001E
RESET : origin = 0xFFFE, length = 0x000
}
and an accompanying SECTIONS directive:
SECTIONS
{
.bss : {} > RAM
.sysmem : {} > RAM
.stack : {} > RAM (HIGH)
}
The HIGH specifier used on the .stack section placement causes the linker to attempt to allocate .stack into the higher addresses within the RAM memory range. The .bss and .sysmem sections are allocated into the lower addresses within RAM. The following example shows a portion of a map file that shows where the given sections are allocated within RAM for a typical program.
.bss 0 00000200 00000270 UNINITIALIZED
00000200 0000011a rtsxxx.lib : defs.c.o (.bss)
0000031a 00000088 : trgdrv.c.o (.bss)
000003a2 00000078 : lowlev.c.o (.bss)
0000041a 00000046 : exit.c.o (.bss)
00000460 00000008 : memory.c.o (.bss)
00000468 00000004 : _lock.c.o (.bss)
0000046c 00000002 : fopen.c.o (.bss)
0000046e 00000002 hello.c.o (.bss)
.sysmem 0 00000470 00000120 UNINITIALIZED
00000470 00000004 rtsxxx .lib : memory.c.o (.sysmem)
.stack 0 000008c0 00000140 UNINITIALIZED
000008c0 00000002 rtsxxx .lib : boot.c.o (.stack)
As shown in the previous example, the .bss and .sysmem sections are allocated at the lower addresses of RAM (0x0200 - 0x0590) and the .stack section is allocated at address 0x08c0, even though lower addresses are available.
Without using the HIGH specifier, the linker allocation would result in the code shown in the following map file contents. The HIGH specifier is ignored if it is used with specific address binding or automatic section splitting (>> operator).
.bss 0 00000200 00000270 UNINITIALIZED
00000200 0000011a rtsxxx.lib : defs.c.o (.bss)
0000031a 00000088 : trgdrv.c.o (.bss)
000003a2 00000078 : lowlev.c.o (.bss)
0000041a 00000046 : exit.c.o (.bss)
00000460 00000008 : memory.c.o (.bss)
00000468 00000004 : _lock.c.o (.bss)
0000046c 00000002 : fopen.c.o (.bss)
0000046e 00000002 hello.c.o (.bss)
.stack 0 00000470 00000140 UNINITIALIZED
00000470 00000002 rtsxxx .lib : boot.c.o (.stack)
.sysmem 0 000005b0 00000120 UNINITIALIZED
000005b0 00000004 rtsxxx .lib : memory.c.o (.sysmem)
10.5.5.2.4. Alignment and Blocking¶
You can tell the linker to place an output section at an address that falls on an n-byte boundary, where n is a power of 2, by using the align keyword. For example, the following code allocates .text so that it falls on a 32-byte boundary:
.text: load = align(32)
Blocking is a weaker form of alignment that allocates a section anywhere within a block of size n. The specified block size must be a power of 2. For example, the following code allocates .bss so that the entire section is contained in a single 128-byte block or begins on that boundary:
.bss: load = block(0x0080)
You can use alignment or blocking alone or in conjunction with a memory area, but alignment and blocking cannot be used together.
10.5.5.2.5. Alignment With Padding¶
As with align, you can tell the linker to place an output section at an address that falls on an n-byte boundary, where n is a power of 2, by using the palign keyword. In addition, palign ensures that the size of the section is a multiple of its placement alignment restrictions, padding the section size up to such a boundary, as needed.
For example, the following code lines allocate .text on a 2-byte boundary within the PMEM area. The .text section size is guaranteed to be a multiple of 2 bytes. Both statements are equivalent:
.text: palign(2) {} > PMEM
.text: palign = 2 {} > PMEM
If the linker adds padding to an initialized output section then the padding space is also initialized. By default, padding space is filled with a value of 0 (zero). However, if a fill value is specified for the output section then any padding for the section is also filled with that fill value. For example, consider the following section specification:
.mytext: palign(8), fill = 0xffffffff {} > PMEM
In this example, the length of the .mytext section is 6 bytes before the palign operator is applied. The contents of .mytext are as follows:
addr content
---- -------
0000 0x1234
0002 0x1234
0004 0x1234
After the palign operator is applied, the length of .mytext is 8 bytes, and its contents are as follows:
addr content
---- -------
0000 0x1234
0002 0x1234
0004 0x1234
0006 0xffff
The size of .mytext has been bumped to a multiple of 8 bytes and the padding created by the linker has been filled with 0xff.
The fill value specified in the linker command file is interpreted as a 16-bit constant. If you specify this code:
.mytext: palign(8), fill = 0xff {} > PMEM
The fill value assumed by the linker is 0x00ff, and .mytext will then have the following contents:
addr content
---- -------
0000 0x1234
0002 0x1234
0004 0x1234
0006 0x00ff
If the palign operator is applied to an uninitialized section, then the size of the section is bumped to the appropriate boundary, as needed, but any padding created is not initialized.
The palign operator can also take a parameter of power2. This parameter tells the linker to add padding to increase the section’s size to the next power of two boundary. In addition, the section is aligned on that power of 2 as well. For example, consider the following section specification:
.mytext: palign(power2) {} > PMEM
Assume that the size of the .mytext section is 120 bytes and PMEM starts at address 0x10020. After applying the palign(power2) operator, the .mytext output section will have the following properties:
name addr size align
------- ---------- ----- -----
.mytext 0x00010080 0x80 128
10.5.5.3. Specifying Input Sections¶
An input section specification identifies the sections from input files that are combined to form an output section. In general, the linker combines input sections by concatenating them in the order in which they are specified. However, if alignment or blocking is specified for an input section, all of the input sections within the output section are ordered as follows:
All aligned sections, from largest to smallest
All blocked sections, from largest to smallest
All other sections, from largest to smallest
The size of an output section is the sum of the sizes of the input sections that it comprises.
The following example shows the most common type of section specification; note that no input sections are listed.
SECTIONS
{
.text:
.data:
.bss:
}
In the example above, the linker takes all the .text sections from the input files and combines them into the .text output section. The linker concatenates the .text input sections in the order that it encounters them in the input files. The linker performs similar operations with the .data and .bss sections. You can use this type of specification for any output section.
You can explicitly specify the input sections that form an output section. Each input section is identified by its filename and section name. If the filename is hyphenated (or contains special characters), enclose it within quotes:
SECTIONS {
.text : /* Build .text output section */
{
f1.c.o(.text) /* Link .text section from f1.c.o */ f2.c.o(sec1) /* Link sec1 section from f2.c.o */ "f3-new.c.o" /* Link ALL sections from f3-new.c.o */ f4.c.o(.text,sec2) /* Link .text and sec2 from f4.c.o */ f5.c.o(.task??) /* Link .task00, .task01, .taskXX, etc. from f5.c.o */
f6.c.o(*_ctable) /* Link sections ending in "_ctable" from f6.c.o */
X*.c.o(.text) /* Link .text section for all files starting with */
/* "X" and ending in ".c.o" */
}
}
It is not necessary for input sections to have the same name as each other or as the output section they become part of. If a file is listed with no sections, all of its sections are included in the output section. If any additional input sections have the same name as an output section but are not explicitly specified by the SECTIONS directive, they are automatically linked in at the end of the output section. For example, if the linker found more .text sections in the preceding example and these .text sections were not specified anywhere in the SECTIONS directive, the linker would concatenate these extra sections after f4.c.o(sec2).
The specifications in the first example above are actually a shorthand method for the following:
SECTIONS
{
.text: { *(.text) }
.data: { *(.data) }
.bss: { *(.bss) }
}
The specification *(.text) means the unallocated .text sections from all input files. This format is useful if:
You want the output section to contain all input sections that have a specified name, but the output section name is different from the input sections’ name.
You want the linker to allocate the input sections before it processes additional input sections or commands within the braces.
The following example illustrates the two purposes above:
SECTIONS
{
.text : {
abc.c.o(xqt)
*(.text)
}
.data : {
*(.data)
fil.c.o(table)
}
}
In this example, the .text output section contains a named section xqt from file abc.c.o, which is followed by all the .text input sections. The .data section contains all the .data input sections, followed by a named section table from the file fil.c.o. This method includes all the unallocated sections. For example, if one of the .text input sections was already included in another output section when the linker encountered *(.text), the linker could not include that first .text input section in the second output section.
Each input section acts as a prefix and gathers longer-named sections. For example, the pattern *(.data) matches .dataspecial. This mechanism enables the use of subsections, which are described in the following section.
10.5.5.4. Using Multi-Level Subsections¶
Subsections can be identified with the base section name and one or more subsection names separated by colons or periods. For example, A:B and A:B:C name subsections of the base section A. Likewise, A.B and A.B.C name the same subsections of the base section A. In certain places in a linker command file specifying a base name, such as A, selects the section A as well as any subsections of A, such as A:B or A:C:D.
A name such as A:B can specify a (sub)section of that name as well as any (multi-level) subsections beginning with that name, such as A:B:C, A:B:OTHER, etc. All subsections of A:B are also subsections of A. A and A:B are supersections of A:B:C. Among a group of supersections of a subsection, the nearest supersection is the supersection with the longest name. Thus, among {A, A:B} the nearest supersection of A:B:C:D is A:B. With multiple levels of subsections, the constraints are the following:
When specifying input sections within a file (or library unit) the section name selects an input section of the same name and any subsections of that name.
Input sections that are not explicitly allocated are allocated in an existing output section of the same name or in the nearest existing supersection of such an output section. An exception to this rule is that during a partial link (specified by the --relocatable linker option) a subsection is allocated only to an existing output section of the same name.
If no such output section described in 2) is defined, the input section is put in a newly created output section with the same name as the base name of the input section
Consider linking input sections with the following names:
europe:north:norway
europe:central:france
europe:south:spain
europe:north:sweden
europe:central:germany
europe:south:italy
europe:north:finland
europe:central:denmark
europe:south:malta
europe:north:iceland
This SECTIONS specification allocates the input sections as indicated in the comments:
SECTIONS
{
nordic: {*(europe:north)
*(europe:central:denmark)} /* the nordic countries */
central: {*(europe:central)} /* france, germany */
therest: {*(europe)} /* spain, italy, malta */
}
This SECTIONS specification allocates the input sections as indicated in the comments:
SECTIONS
{
islands: {*(europe:south:malta)
*(europe:north:iceland)} /* malta, iceland */
europe:north:finland : {} /* finland */
europe:north : {} /* norway, sweden */
europe:central : {} /* germany, denmark */
europe:central:france: {} /* france */
/* (italy, spain) go into a linker-generated output section "europe" */
}
Note
Upward Compatibility of Multi-Level Subsections
Existing linker commands that use the existing single-level subsection features and which do not contain section names containing multiple colon characters continue to behave as before. However, if section names in a linker command file or in the input sections supplied to the linker contain multiple colon characters, some change in behavior could be possible. You should carefully consider the impact of the rules for multiple levels to see if it affects a particular system link.
10.5.5.5. Specifying Library or Archive Members as Input to Output Sections¶
You can specify one or more members of an object library or archive for input to an output section. Consider this SECTIONS directive:
SECTIONS
{
boot > BOOT1
{
-l rtsXX.lib<boot.c.o> (.text)
-l rtsXX.lib<exit.c.o strcpy.c.o> (.text)
}
.rts > BOOT2
{
-l rtsXX.lib (.text)
}
.text > RAM
{
* (.text)
}
}
In Example 9, the .text sections of boot.c.o, exit.c.o, and strcpy.c.o are extracted from the run-time-support library and placed in the .boot output section. The remainder of the run-time-support library object that is referenced is allocated to the .rts output section. Finally, the remainder of all other .text sections are to be placed in section .text.
An archive member or a list of members is specified by surrounding the member name(s) with angle brackets < and > after the library name. Any object files separated by commas or spaces from the specified archive file are legal within the angle brackets.
The --library option (which normally implies a library path search be made for the named file following the option) listed before each library in Example 9 is optional when listing specific archive members inside < >. Using < > implies that you are referring to a library.
To collect a set of the input sections from a library in one place, use the --library option within the SECTIONS directive. For example, the following collects all the .text sections from rtsv4_A_be_eabi.lib into the .rtstest section:
SECTIONS
{
.rtstest { -l rtsv4_A_be_eabi.lib(.text) } > RAM
}
Note
SECTIONS Directive Effect on --priority
Specifying a library in a SECTIONS directive causes that library to be entered in the list of libraries that the linker searches to resolve references. If you use the --priority option, the first library specified in the command file will be searched first.
10.5.5.6. Allocation Using Multiple Memory Ranges¶
The linker allows you to specify an explicit list of memory ranges into which an output section can be allocated. Consider the following example:
MEMORY
{
P_MEM1 : origin = 0x02000, length = 0x01000
P_MEM2 : origin = 0x04000, length = 0x01000
P_MEM3 : origin = 0x06000, length = 0x01000
P_MEM4 : origin = 0x08000, length = 0x01000
}
SECTIONS
{
.text : { } > P_MEM1 | P_MEM2 | P_MEM4
}
The | operator is used to specify the multiple memory ranges. The .text output section is allocated as a whole into the first memory range in which it fits. The memory ranges are accessed in the order specified. In this example, the linker first tries to allocate the section in P_MEM1. If that attempt fails, the linker tries to place the section into P_MEM2, and so on. If the output section is not successfully allocated in any of the named memory ranges, the linker issues an error message.
With this type of SECTIONS directive specification, the linker can seamlessly handle an output section that grows beyond the available space of the memory range in which it is originally allocated. Instead of modifying the linker command file, you can let the linker move the section into one of the other areas.
10.5.5.7. Automatic Splitting of Output Sections Among Non-Contiguous Memory Ranges¶
The linker can split output sections among multiple memory ranges for efficient allocation. Use the >> operator to indicate that an output section can be split, if necessary, into the specified memory ranges:
MEMORY
{
P_MEM1 : origin = 0x2000, length = 0x1000
P_MEM2 : origin = 0x4000, length = 0x1000
P_MEM3 : origin = 0x6000, length = 0x1000
P_MEM4 : origin = 0x8000, length = 0x1000
}
SECTIONS
{
.text: { *(.text) } >> P_MEM1 | P_MEM2 | P_MEM3 | P_MEM4
}
In this example, the >> operator indicates that the .text output section can be split among any of the listed memory areas. If the .text section grows beyond the available memory in P_MEM1, it is split on an input section boundary, and the remainder of the output section is allocated to P_MEM2 | P_MEM3 | P_MEM4.
The | operator is used to specify the list of multiple memory ranges.
You can also use the >> operator to indicate that an output section can be split within a single memory range. This functionality is useful when several output sections must be allocated into the same memory range, but the restrictions of one output section cause the memory range to be partitioned. Consider the following example:
MEMORY
{
RAM : origin = 0x1000, length = 0x8000
}
SECTIONS
{
.special: { f1.c.o(.text) } load = 0x4000
.text: { *(.text) } >> RAM
}
The .special output section is allocated near the middle of the RAM memory range. This leaves two unused areas in RAM: from 0x1000 to 0x4000, and from the end of f1.c.o(.text) to 0x8000. The specification for the .text section allows the linker to split the .text section around the .special section and use the available space in RAM on either side of .special.
The >> operator can also be used to split an output section among all memory ranges that match a specified attribute combination. For example:
MEMORY
{
P_MEM1 (RWX) : origin = 0x1000, length = 0x2000
P_MEM2 (RWI) : origin = 0x4000, length = 0x1000
}
SECTIONS
{
.text: { *(.text) } >> (RW)
}
The linker attempts to allocate all or part of the output section into any memory range whose attributes match the attributes specified in the SECTIONS directive.
This SECTIONS directive has the same effect as:
SECTIONS
{
.text: { *(.text) } >> P_MEM1 | P_MEM2}
}
Certain sections should not be split:
Certain sections created by the compiler, including:
The .cinit section, which contains the auto-initialization table for C/C++ programs
The .pinit section, which contains the list of global constructors for C++ programs
An output section with an input section specification that includes an expression to be evaluated. The expression may define a symbol that is used in the program to manage the output section at run time.
An output section that has a START(), END(), OR SIZE() operator applied to it. These operators provide information about a section’s load or run address, and size. Splitting the section may compromise the integrity of the operation.
The run allocation of a UNION. (Splitting the load allocation of a UNION is allowed.)
If you use the >> operator on any of these sections, the linker issues a warning and ignores the operator.