5.4. How the Assembler Handles Sections¶
The assembler identifies the portions of an assembly language program that belong in a given section. The assembler has the following directives that support this function:
.bss
.data
.sect
.text
.usect
The .bss and .usect directives create uninitialized sections; the .text, .data, and .sect directives create initialized sections.
You can create subsections of any section to give you tighter control of the memory map. Subsections are created using the .sect and .usect directives. Subsections are identified with the base section name and a subsection name separated by a colon; see Subsections.
Note
If you do not use a section directive, the assembler assembles everything into the .text section.
5.4.1. Uninitialized Sections¶
Uninitialized sections reserve space in C29x memory; they are usually placed in RAM. These sections have no actual contents in the object file; they simply reserve memory. A program can use this space at run time for creating and storing variables.
Uninitialized data areas are built by using the following assembler directives.
The .bss directive reserves space in the .bss section.
The .usect directive reserves space in a specific uninitialized user-named section.
Each time you invoke the .bss or .usect directive, the assembler reserves additional space in the .bss or the user-named section. The syntax is:
.bss symbol,size in bytes[, alignment [, bank offset] ] |
|
symbol |
.usect “section name“,size in bytes[, alignment[, bank offset] ] |
symbol points to the first byte reserved by this invocation of the .bss or .usect directive. The symbol corresponds to the name of the variable for which you are reserving space. It can be referenced by any other section and can also be declared as a global symbol (with the .global directive).
size in bytes is an absolute expression. The .bss directive reserves size in bytes bytes in the .bss section. The .usect directive reserves size in bytes bytes in section name. For both directives, you must specify a size; there is no default value.
alignment is an optional parameter. It specifies the minimum alignment in bytes required by the space allocated. The default value is byte aligned; this option is represented by the value 1. The value must be a power of 2.
bank offset is an optional parameter. It ensures that the space allocated to the symbol occurs on a specific memory bank boundary. The bank offset measures the number of bytes to offset from the alignment specified before assigning the symbol to that location.
section name specifies the user-named section in which to reserve space. See User-Named Sections.
Initialized section directives (.text, .data, and .sect) change which section is considered the current section (see Current Section). However, the .bss and .usect directives do not change the current section; they simply escape from the current section temporarily. Immediately after a .bss or .usect directive, the assembler resumes assembling into whatever the current section was before the directive. The .bss and .usect directives can appear anywhere in an initialized section without affecting its contents. For an example, see Using Sections Directives.
The .usect directive can also be used to create uninitialized subsections. See Subsections for more information on creating subsections.
The .common directive is similar to directives that create uninitialized data sections, except that common symbols are created by the linker instead.
5.4.2. Initialized Sections¶
Initialized sections contain executable code or initialized data. The contents of these sections are stored in the object file and placed in C29x memory when the program is loaded. Each initialized section is independently relocatable and may reference symbols that are defined in other sections. The linker automatically resolves these references. The following directives tell the assembler to place code or data into a section. The syntaxes for these directives are:
.text |
|
.data |
|
.sect “section name“ |
The .sect directive can also be used to create initialized subsections. See Subsections, for more information on creating subsections.
5.4.3. User-Named Sections¶
User-named sections are sections that you create. You can use them like the default .text, .data, and .bss sections, but each section with a distinct name is kept distinct during assembly.
For example, repeated use of the .text directive builds up a single .text section in the object file. This .text section is allocated in memory as a single unit. Suppose there is a portion of executable code (perhaps an initialization routine) that you want the linker to place in a different location than the rest of .text. If you assemble this segment of code into a user-named section, it is assembled separately from .text, and you can use the linker to allocate it into memory separately. You can also assemble initialized data that is separate from the .data section, and you can reserve space for uninitialized variables that is separate from the .bss section.
These directives let you create user-named sections:
The .usect directive creates uninitialized sections that are used like the .bss section. These sections reserve space in RAM for variables.
The .sect directive creates initialized sections, like the default .text and .data sections, that can contain code or data. The .sect directive creates user-named sections with relocatable addresses.
The syntaxes for these directives are:
symbol |
.usect “section name“, size in bytes[, alignment[, bank offset] ] |
.sect “section name“ |
The maximum number of sections is 232-1 (4294967295).
The section name parameter is the name of the section. For the .usect and .sect directives, a section name can refer to a subsection; see Subsections for details.
Each time you invoke one of these directives with a new name, you create a new user-named section. Each time you invoke one of these directives with a name that was already used, the assembler resumes assembling code or data (or reserves space) into the section with that name. You cannot use the same names with different directives. That is, you cannot create a section with the .usect directive and then try to use the same section with .sect.
5.4.4. Current Section¶
The assembler adds code or data to one section at a time. The section the assembler is currently filling is the current section. The .text, .data, and .sect directives change which section is considered the current section. When the assembler encounters one of these directives, it stops assembling into the current section (acting as an implied end of current section command). The assembler sets the designated section as the current section and assembles subsequent code into the designated section until it encounters another .text, .data, or .sect directive.
If one of these directives sets the current section to a section that already has code or data in it from earlier in the file, the assembler resumes adding to the end of that section. The assembler generates only one contiguous section for each given section name. This section is formed by concatenating all of the code or data which was placed in that section.
5.4.5. Section Program Counters¶
The assembler maintains a separate program counter for each section. These program counters are known as section program counters, or SPCs.
An SPC represents the current address within a section of code or data. Initially, the assembler sets each SPC to 0. As the assembler fills a section with code or data, it increments the appropriate SPC. If you resume assembling into a section, the assembler remembers the appropriate SPC’s previous value and continues incrementing the SPC from that value.
The assembler treats each section as if it began at address 0; the linker relocates the symbols in each section according to the final address of the section in which that symbol is defined. See Symbolic Relocations for information on relocation.
5.4.6. Subsections¶
A subsection is created by creating a section with a colon or period in its name. Subsections are logical subdivisions of larger sections. Subsections are themselves sections and can be manipulated by the assembler and linker.
The assembler has no internal concept of subsections; to the assembler, a colon or period in the name is not special. Subsections named .text:rts and .text.rts are different sections and are considered completely unrelated to the parent section .text. The assembler does not combine such subsections with their parent sections.
In contrast, the linker recognizes both colons and periods as subsection delimiters. To the linker, both .text:rts and .text.rts reference the same subsection of the .text section. See Using Multi-Level Subsections.
Subsections are used to keep parts of a section as distinct sections so that they can be separately manipulated. For instance, by placing each function and object in a uniquely-named subsection, the linker gets a finer-grained view of the section for memory placement and unused-function elimination.
By default, when the linker sees a SECTION directive in the linker command file like “.text”, it gathers .text and all subsections of .text into one large output section named “.text”. You can instead use the SECTION directive to control the subsection independently. See SECTIONS Directive Syntax for an example.
You can create subsections in the same way you create other user-named sections: by using the .sect or .usect directive.
The syntaxes for a subsection name are:
symbol |
.usect “section_name:subsection_name“, size in bytes[, alignment[, bank offset] ] |
.sect “section_name:subsection_name“ |
A subsection is identified by the base section name followed by a colon or period and the name of the subsection. The subsection name may not contain any spaces.
A subsection can be allocated separately or grouped with other sections using the same base name. For example, you create a subsection called _func within the .text section:
.sect ".text:_func"
Using the linker’s SECTIONS directive, you can allocate .text:_func separately, or with all the .text sections.
You can create two types of subsections:
Uninitialized subsections are created using the .usect directive. See Uninitialized Sections.
Initialized subsections are created using the .sect directive. See Initialized Sections.
Subsections are placed in the same manner as sections. See The SECTIONS Directive for information on the SECTIONS directive.
5.4.7. Using Sections Directives¶
The example below shows how you can build sections incrementally, using the sections directives to swap back and forth between the different sections. You can use sections directives to begin assembling into a section for the first time, or to continue assembling into a section that already contains code. In the latter case, the assembler simply appends the new code to the code that is already in the section.
The format shown below is a listing file. The example shows how the SPCs are modified during assembly. A line in a listing file has four fields:
Field 1 |
contains the source code line counter. |
Field 2 |
contains the section program counter. |
Field 3 |
contains the object code. |
Field 4 |
contains the original source statement. |

Figure 5.2 Using Sections Directives¶
As the figure below shows, the file in the example above creates five sections:
.text |
contains six 32-bit words of object code. |
.data |
contains seven 32-bit words of initialized data. |
vectors |
is a user-named section created with the .sect directive; it contains two 32-bit words of initialized data. |
.bss |
reserves ten bytes in memory. |
newvars |
is a user-named section created with the .usect directive; it reserves eight bytes in memory. |
The second column shows the object code that is assembled into these sections; the first column shows the source statements that generated the object code.
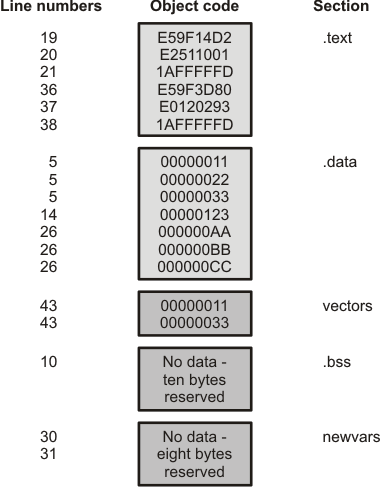
Figure 5.3 Object Code Generated by the Above Assembly Code¶