1.引言¶
本章介绍了一个软件开发流程,可用于提高在 C2000™ MCU 中 TMS320C28x CPU 上执行的 C 代码的性能。
1.1.软件开发流程¶
C28x CPU 的软件开发可分为以下几个阶段:
阶段 1
在 C2000 器件上编写、编译和调试应用程序。在此阶段,禁用编译器优化以实现最佳调试体验。此阶段的重点是功能性和正确性。但是,在此阶段需要牢记一些规则,以生成高效的 C2000 代码并避免以后返工。有关详细信息,请参阅初始开发。
阶段 2
对应用程序进行性能分析以确定应用程序花费大部分运行时间的代码区域。在某些情况下,可以明显看出应用程序将大部分时间花在一两个 ISR 上。在这种情况下,性能分析可帮助确定 ISR 中的哪些函数占用了大部分 ISR 运行时。
性能分析用于将优化工作集中在占大部分运行时的函数上。有几种不同的性能分析方法,有关详细信息,请参阅性能分析。
阶段 3
优化应用程序以满足性能和代码大小限制。典型步骤包括:
- 将最常执行的函数和相关数据放在 RAM 中
- 启用适当的编译器选项:
- 在编译器中利用优化传递的选项 - 优化级别、内联等。
- 利用硬件特性(FPU、TMU 等)的选项
- 尽可能使用 TI 的优化库(例如数字控制库)
- 向编译器提供更多信息以帮助其优化(pragmas、restrict 等)
- 使用 CLA
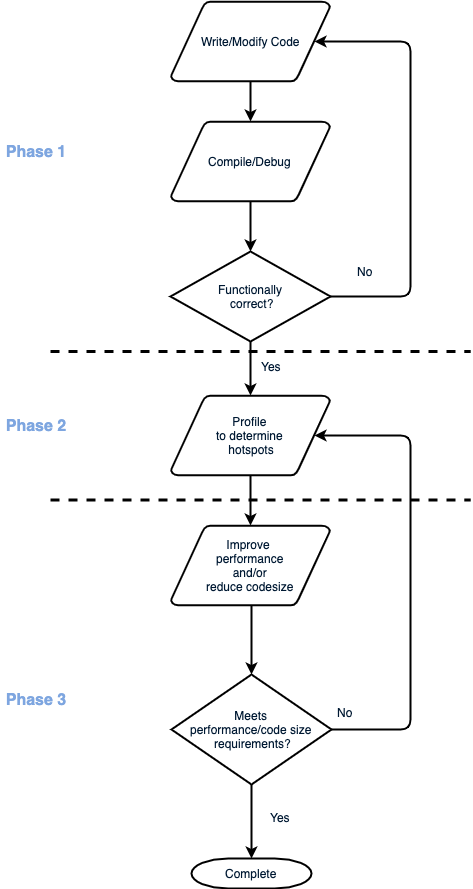
图 1.1 软件开发 - 性能分析和优化
有关详细信息,请参阅改进性能。
阶段 2 和阶段 3 是迭代的。尝试优化,测量性能/代码大小并重复。建议设置一个自检应用程序,以便在优化期间检查其正确性。
1.2.处理元件¶
- C28x CPU
- C28x CPU 是一个 32 位定点处理器。它结合了 RISC 功能,例如单周期指令执行和寄存器到寄存器操作。CPU 修改后的 Harvard 架构使指令和数据获取能够并行执行。
- 浮点单元
- FPU
- FPU 可通过增加支持 IEEE 单精度浮点运算的寄存器和指令来扩展 C28x 定点 CPU 的功能。
- FPU64
- FPU64 可通过增加支持 IEEE 单精度和双精度浮点运算的寄存器和指令来扩展 C28x 定点 CPU 的功能。
- 三角函数加速器
- TMU
- TMU 通过添加指令和利用可加速执行常见三角函数和算术运算的现有 FPU 指令来扩展 C28x+FPU 的功能。
- Viterbi、复杂数学和 CRC 单元
- VCU
- VCU 处理器可通过增加支持以下算法类型的寄存器和指令来扩展 C28x CPU 的功能。Viterbi 解码、循环冗余校验 (CRC)、复杂数学。
有关 C28x CPU、FPU、TMU 和 VCU 的更多信息,请参见以下文档:
控制律加速器 (CLA) 控制律加速器是一个 32 位浮点数学加速器,在大多数 C2000 MCU 上都很常见。它有助于快速控制算法的并发处理。有关 CLA 的详细信息,请参阅器件 TRM 中的“CLA”一章。